¶ title: Kubernetes: Cours EPSI
description: Kubernetes reference
published: true
date: 2026-04-03T23:57:42.941Z
tags: kubernetes
editor: markdown
dateCreated: 2023-09-23T14:54:59.942Z

¶ Introduction
¶ Historique
Historiquement, Kubernetes ("capitaine" en grec ancien) a été développé en interne chez Google notamment par Joe Beda, Brendan Burns, Craig McLuckie, rapidement rejoints par Brian Grant et Tom Hockin (accessoirement un des modérateurs fondateurs du subreddit /r/kubernetes) et annoncé pour la première fois par Google en 2014. Kubernetes est dérivé d'Omega, lui même inspiré de Borg ("Toute résistance est inutile"©), le système d'orchestration interne de Google.

Google a présenté Kubernetes comme le successeur de Borg, même si Kubernetes n'est pas utilisé pour la gestion de l'infrastructure même de Google (les limites de kubernetes l'empêchent: 5000 nodes max, 150000 "pods" et 300000 containers max. Bon il y a déjà de quoi faire  ).
).
C'est un logiciel Open-Source, désormais développé par de nombreux contributeurs sous l'égide de la Linux Foundation et de la CNCF (Cloud Native Computing Foundation). La version 1.0 est sortie en 2015, et nous sommes (Avril 2026) actuellement à la version 1.35 (bientôt 1.36).
Si le rythme de sortie des nouvelles versions était assez rapide par le passé, depuis 2020~ les choses se sont stabilisées, et on assiste désormais à une release majeure tous les six mois environ.
Kubernetes est un logiciel d'orchestration de containers, c'est à dire qu'il est en charge du déploiement, du dimensionnement ("scaling"), de l'accès réseau (Services, Ingresses), de l'attribution d'espace de stockage, de l'évolution, de la haute-disponibilité de charges de travail s'exécutant dans des "pods". Mais qu'est-ce qu'un "pod"?
L'unité de base de Kubernetes est le "pod", qui peut contenir un seul container, ou plusieurs (ex: un pod "nginx-php-redis" pourrait contenir un conteneur nginx, un conteneur php-fpm et un conteneur redis, communiquant entre eux via localhost).
Kubernetes est notamment utilisé par:
- Mercedes
- Slack
- Google (enfin, ils le vendent, le service, hein)
- Nubank (poke Valentin?)
- Spotify
- Airbnb
- etc, etc, etc...
¶ Concurrence
¶ Docker Swarm
Docker Swarm est la solution d'orchestration de containers de Mirantis (initialement de Docker, revendu par la suite). Toujours maintenue mais de moins en moins utilisée, ses avantages sont l'absence de control-planes et une plus grande simplicité de mise en oeuvre, mais avec moins de possibilité de gestion du trafic, des services, de l'autoscaling, etc...
¶ Hashicorp Nomad
Plus simple à mettre en oeuvre que Kubernetes, avec une courbe d'apprentissage plus "soft", et utilisé par de nombreuses entreprises, Nomad est une solution tout à fait adaptée et à considérer par rapport à Kubernetes. Elle est axée infrastructures on-premise et IoT du fait de sa simplicité et de sa légèreté, et est aussi capable de s'interfacer avec l'API de Kubernetes. Utilisé notamment par:
- Autodesk
- Roblox
- AmpleOrganics (Canada, vente de produits à base de... hum... cannabis. cough)
Une technologie à surveiller, qui peut correspondre à des besoins ne nécessitant pas la complexité - apparente - de Kubernetes.
¶ Architecture d'un cluster Kubernetes
¶ Composition d'un cluster Kubernetes
Un cluster Kubernetes est composé de deux types de machines (physiques ou virtuelles, voire, conteneurs type LXC ou Docker/Podman (KinD: Kubernetes in Docker):
- Un ou plusieurs (minimum 3 si plusieurs pour des questions de quorum) control-planes (anciennement master) qui sont en charge de l'API, de l'ordonnancement et du contrôle du bon fonctionnement des charges de travail.
- Workers dont le seul rôle est d'exécuter les pods constituant les charges de travail. Ils n'exécutent aucune charge de travail relative au bon fonctionnement du cluster et sont donc facilement interchangeables/jetables.
¶ Eléments essentiels au fonctionnement d'un cluster Kubernetes
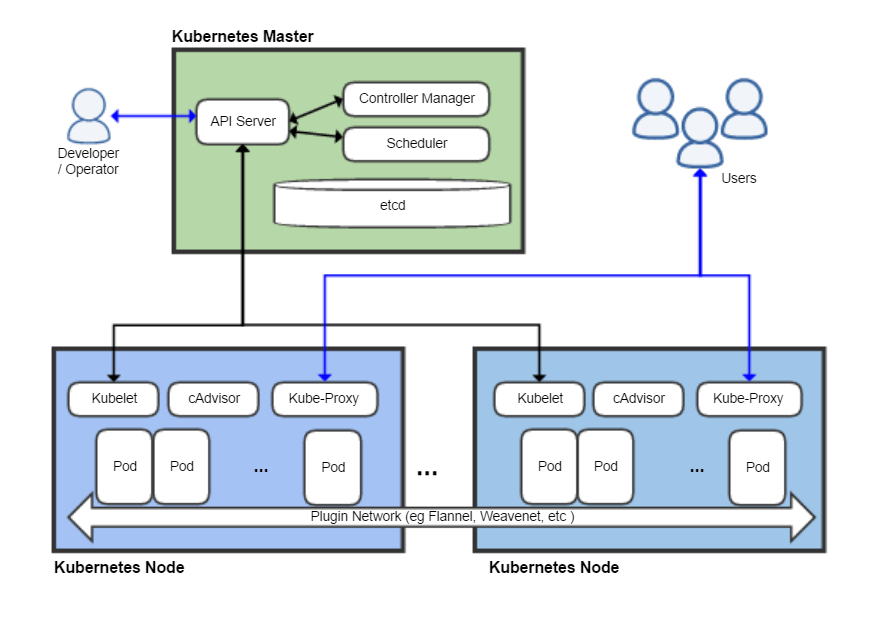
Pour fonctionner, notre cluster Kubernetes a besoin de plusieurs choses:
- une CRI, Container Resource Interface, lui permettant de manipuler... des containers. Dans le temps on trouvait souvent Docker, cependant il a été remplacé depuis Kubernetes 1.23 (si je me rappelle bien), et désormais on utilise principalement containerd, CRI-O, podman ou runc.
- Une CNI, Container Network Interface. On peut citer Flannel, Calico, Cilium, Weave-net... Le but d'une CNI est d'assigner des IPs (internes au cluster) à nos pods et services, de permettre la communication de ces pods et services entre les différents noeuds du cluster (en général soit via des VxLANs, IPVS, ou eBPF)
- D'un serveur d'API (apiserver) joignable depuis l'extérieur
- D'un scheduler, en charge de la distribution des charges de travail entre les différents noeuds du cluster
- D'un controller-manager dont le but est de vérifier à intervalles réguliers le bon fonctionnement des charges de travail, et d'avertir l'apiserver en cas de problème.
- D'une base de données conservant l'état du cluster en temps réel. Kubernetes utilise par défaut etcd, une base de données clef/valeur. Il est évidemment important de bien veiller à la réplication de cette base de données et d'en effectuer des backups réguliers lorsqu'on est en production!
- D'un outil de monitoring de base pour vérifier les ressources de chaque noeud du cluster, afin de ne pas déployer sur un noeud des charges de travail dépassant la capacité utilisable de ce noeud.
- D'un serveur DNS, généralement CoreDNS, interne au cluster. Par défaut le domaine du cluster est
cluster.local. Un Service Kubernetes (on va l'appeler... postgres) présent dans un Namespace que nous allons appeler databases aura pour FQDN: postgres.databases.svc.cluster.local. Dès lors, un FQDN Kubernetes est toujours de la forme:nom-de-la-ressource.namespace.type-de-ressource.domain.tld. - Enfin, kubelet s'occupe sur chaque noeud du cluster de "discuter" avec la CRI pour lui faire créer les différents containers voulus ainsi que leurs caractéristiques réseau. Kubelet down == node down.
- Optionnel mais pratique (enfin indispensable dès qu'on veut faire du stateful avec Kubernetes): un peu de storage distant (NFS, iSCSI, S3, gcloud disk...), ou local (Longhorn, rook-ceph, piraeus-datastore...)
Un petit schéma honteusement pompé de Wikipedia (merci, Wikipedia!):
¶ Installation
Nous allons commencer par mettre en place notre propre cluster Kubernetes sur deux petites VMs Debian Stable (bookworm, donc) et une troisième VM pour le storage:
- Une VM 2 vCores, 4Go RAM, 30Go disque qui nous servira de control-plane
- Une VM 2 vCores, 6Go RAM, 30Go disque qui nous servira de worker
Nos VMs doivent avoir des IPs fixes et des hostnames différents (notamment si clone)!!
Sur nos VMs control-plane et worker, nous installerons aussi le paquet nfs-common.
Sur notre VM NFS, on installera le paquet nfs-kernel-server, on créera un répertoire /srv/k0s/nfsprov et on éditera notre fichier /etc/exports de la sorte:
/srv/k0s/nfsprov IP_VM1/32(rw,sync,no_subtree_check,no_root_squash,anonuid=1000,anongid=1000)
/srv/k0s/nfsprov IP_VM2/32(rw,sync,no_subtree_check,no_root_squash,anonuid=1000,anongid=1000)
... et ainsi de suite si on a plusieurs workers.
Et pour finir, un petit sudo exportfs -a pour exporter notre répertoire en NFS à nos VMs kubernetes.
Bien sûr, nous mettrons en place un setup plus costaud sur le cluster de virtualisation de l'EPSI pendant l'atelier, mais ces deux petites machines nous permettront de découvrir tranquillement l'API de Kubernetes. Bien évidemment, si vous avez plus de 8Go de RAM, n'hésitez pas à "gonfler" un peu la conf' côté RAM ou à créer une VM supplémentaire de configuration équivalente (histoire d'avoir deux workers) 
¶ Setup
Tout d'abord, on va voter entre plusieurs solutions:
- La solution "oldschool", install de kubernetes via debian+kubeadm. L'avantage ici est que l'on pourra "voir" tous les composants de notre cluster (c'est à dire nos nodes, les charges de travail propres au cluster, etc). Plus orienté sysadmins
- La solution "easy-peasy", où on va installer kubernetes via k0s (développé par Mirantis, ils se sont prévus une porte de sortie de Docker Swarm ). Nous ne verrons pas nos controlplanes, et nous n'aurons pas accès aux ressources du cluster lui même (en effet, k0s intègre toutes ces ressources (apiserver, scheduler, controller-manager, etcd)) dans un seul exécutable (k0s, justement). Plus orienté dev'. On devra néanmoins installer nous même LoadBalancer et Ingress, mais on y vient plus loin.
- La solution un peu plus fun avec k0sctl pour déployer de façon quasi-automatique notre cluster (idéalement, on utiliserait Terraform pour déployer nos VMs en amont)
- La solution "easy-peasy" mais avec un peu plus de détails, en utilisant k3s. Il intègre déjà un LoadBalancer minimaliste et un Ingress (Traefik, je n'en suis pas super fan mais bon, il fera le job') - ce qui peut nous embêter car idéalement, j'aimerai vous faire utiliser un load-balancer et un Ingress que l'on retrouve plus souvent sur du kubernetes on-prem : MetalLB qui peut annoncer des IPs via ARP ou BGP (la classe), et Ingress-nginx que l'on retrouve vraiment partout.
¶ debian+ kubeadm (hardcore )
¶ debian+k0s

On va d'abord installer l'exécutable k0s sur nos deux machines (oui, curl pipé dans sh c'est laid.)
apt install curl iptables
curl -sSLf https://get.k0s.sh | sudo sh
Nous allons tout d'abord configurer notre controlplane. Sur notre VM controlplane:
sudo k0s config create > k0s.yaml
sudo k0s install controller -c k0s.yaml
sudo k0s start
Et... c'est tout! On peut vérifier rapidement que le nécessaire est prêt:
sudo k0s status
Version: v1.27.4+k0s.0
Process ID: 1132
Role: controller
Workloads: false
SingleNode: false
Toujours sur notre controlplane, nous allons créer le token qui va permettre à notre worker de rejoindre le cluster:
sudo k0s token create --role=worker > token
Et le copier rapidement sur notre VM worker, soit via scp, soit via le bon vieux netcat/nc:
# sur le controlplane:
nc -l -p 1234 < token
# sur le worker:
nc IP_CONTROL_PLANE 1234 > token
Ctrl-C
Maintenant, sur notre worker, il nous suffit de lancer la commande:
sudo k0s install worker --token-file /path/to/token
sudo k0s start
On peut désormais, sur notre controlplane, vérifier le déploiement de notre worker via les commandes:
sudo k0s kubectl get nodes
sudo k0s kubectl get pods -A -o wide
Vous noterez que dans le cas de k0s, notre control-plane n'apparaît pas dans la liste des noeuds disponibles. meh 
On va se simplifier un peu la vie, en effet, taper sudo k0s kubectl ... risque de vite devenir pénible, nous allons donc simplement installer le "vrai" kubectl sur notre controlplane (ou sur votre poste de travail) et récupérer le kubeconfig, le fichier de configuration de l'administrateur du cluster:
# attention le \ est à supprimer si vous copiez ça
# sur une seule ligne ;)
curl -LO "https://dl.k8s.io/release/$(curl -L -s \
https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
chmod 755 kubectl && sudo mv kubectl /usr/local/bin/
mkdir .kube
sudo cp /var/lib/k0s/pki/admin.conf .kube/config
sudo chown -R 1000:1000 .kube
# on teste que tout fonctionne correctement:
kubectl get nodes
¶ debian+k0s via k0sctl (very cool)
Ici, nous allons déployer k0s quasi automatiquement via l'utilitaire k0sctl (https://github.com/k0sproject/k0sctl).
Attention, pour se faire, surtout si vos VMs sont des clones, quelques manipulations sont nécessaires pour préparer nos hôtes:
- Vérifier que le fichier
/etc/machine-idest unique à chaque VM. Si ce n'est pas le cas, supprimer les fichiers/var/lib/dbus/machine-idet/etc/machine-idpuis régénérer le machine-id via la commandesystemd-machine-id-setup. - Vos VMs ne doivent pas avoir le même hostname (
man hostnamectl) - Soit configurer sudo pour votre utilisateur en mode NOPASSWD.
- Soit ajouter votre clef publique SSH favorite au fichier
authorized_keysdu compte root de vos VMs.
Sur votre laptop, dans un répertoire de votre choix, exécutez la commande:
k0sctl init > k0scluster.yaml
Qui va nous générer un fichier yaml (how strange... ) contenant un squelette par défaut, que nous allons modifier pour "coller" à notre setup, exemple:
apiVersion: k0sctl.k0sproject.io/v1beta1
kind: Cluster
metadata:
name: k0s-cluster
spec:
hosts:
- ssh:
address: 192.168.1.52
user: root
port: 22
keyPath: /home/lidstah/.ssh/id_rsa
role: controller
- ssh:
address: 192.168.1.53
user: root
port: 22
keyPath: /home/lidstah/.ssh/id_rsa
role: worker
Comme vous pouvez le constater, la syntaxe est extrêmement simple et va nous permettre de déployer k0s sur les machines renseignées avec les rôles désirés.
Attention cependant, pour le moment k0sctl n'est pas capable de supprimer une machine (en ajouter n'est pas un problème).
Afin de déployer k0s sur notre mini-cluster, il ne nous reste dès lors qu'à exécuter la commande:
k0sctl apply --disable-telemetry --config k0scluster.yaml
Une fois le cluster déployé et opérationnel, on va pouvoir récupérer notre fichier kubeconfig:
k0sctl kubeconfig > kubeconfig
# ou, si on veut se simplifier la vie:
k0sctl kubeconfig > ~/.kube/config
On peut désormais utiliser kubectl soit directement si on a installé notre fichier de configuration de cluster dans ~/.kube/config soit en précisant le fichier de configuration à la ligne de commande, par exemple pour afficher les noeuds de notre cluster: kubectl --kubeconfig ./kubeconfig get nodes.
Ce qui devrait nous donner quelque chose du style:
lidstah@vega:~/src/k0sctl$ kubectl --kubeconfig ./kubeconfig get nodes
NAME STATUS ROLES AGE VERSION
k0s-worker1 Ready <none> 79m v1.27.4+k0s
k0s-worker2 Ready <none> 79m v1.27.4+k0s
¶ debian + k3s
Alors, c'est très simple:
sur la VM que nous voulons utiliser comme control-plane:
curl -sfL https://get.k3s.io | sh -
et sur les VMs que nous voulons utiliser comme workers:
curl -sfL https://get.k3s.io | K3S_URL=https://myserver:6443 K3S_TOKEN=mynodetoken sh -
Où K3S_URL est donc l'IP de notre control-plane et K3S_TOKEN le token récupéré sur notre control-plane dans le fichier /var/lib/rancher/k3s/server/node-token.
Et voilà!
Pour pouvoir utiliser kubectl depuis notre control-plane:
mkdir ~/.kube
sudo cp /etc/rancher/k3s/k3s.yaml ~/.kube/config
sudo chown 1000:1000 ~/.kube/config
chmod 600 ~/.kube/config
echo "export KUBECONFIG=~/.kube/config" >> .bashrc
export KUBECONFIG=~/.kube/config
kubectl get nodes
¶ Une solution à garder en vue, notamment pour l'atelier à suivre: Talos Linux
Talos Linux est une distribution gnu/linux dédiée à Kubernetes. Elle est immutable, pèse ~80Mo, et n'embarque que le strict nécessaire pour exécuter Kubernetes. De plus, la configuration et l'installation des différents nodes est purement déclarative, en YAML. Pas de SSH, pas de shell, mais une API gérée par talosctl pour manipuler notre cluster, et des fichiers YAML pour décrire nos différentes machines. J'aime beaucoup (mon homelab comme ma prod' chez mes clients utilisent cette distribution). Donc je suis partial
¶ kubectl
kubectl est l'outil de manipulation des objets de l'API du Kubernetes par défaut. Il nous permet de créer, détruire, modifier rapidement des objets de l'API mais aussi d'obtenir des informations et même des explications sur ces objets.
Il existe heureusement un module d'autocomplétion des commandes de kubectl qui va nous permettre de créer un fichier sourçable (par exemple dans notre .bash_profile) via la commande kubectl completion. La commande kubectl completion -h vous fournira de plus amples informations à ce sujet.
¶ Commandes de base
¶ kubectl config
kubectl config et toutes ses sous commandes permettent de manipuler les fichiers de configuration de cluster (.kube/config,kubeconfig, etc).
En effet, il arrive plus que souvent de travailler sur plusieurs clusters, ou dans plusieurs namespaces, il est alors primordial de pouvoir facilement changer de contexte (par exemple pour travailler sur un autre cluster ou dans un autre namespace sans avoir à spécifier d'interminables --kubeconfig et autres -n autre-namespace).
Il faut savoir que nous pouvons "concaténer" nos fichiers de configuration Kubernetes dans une variable d'environnement, la variable KUBECONFIG. Dès lors il est très simple d'ajouter ou supprimer des ressources (et donc des contextes) à cette variable.
Imaginons que nous ayons un cluster K0S, dont le fichier kubeconfig se trouve dans ~/src/k0s/kubeconfig et un cluster Talos Linux dont le kubeconfig se trouve à l'emplacement par défaut, c'est à dire ~/.kube/config. On peut facilement "concaténer" ces deux fichiers de configuration via la commande (qu'on peut bien évidemment ajouter à nos fichiers de profils habituels):
export KUBECONFIG="${KUBECONFIG}:~/.kube/config:~/src/k0s/kubeconfig"
Dès lors, la commande kubectl config view va nous indiquer quels contextes représentent tel ou tel cluster:
kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.1.52:6443
name: k0s-cluster
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.1.220:6443
name: talos-k8s-cluster
contexts:
- context:
cluster: talos-k8s-cluster
namespace: default
user: admin@talos-k8s-cluster
name: admin@talos-k8s-cluster
- context:
cluster: k0s-cluster
user: admin
name: k0s-cluster
current-context: admin@talos-k8s-cluster
kind: Config
preferences: {}
users:
- name: admin
user:
client-certificate-data: DATA+OMITTED
client-key-data: DATA+OMITTED
- name: admin@talos-k8s-cluster
user:
client-certificate-data: DATA+OMITTED
client-key-data: DATA+OMITTED
On peut voir ici que j'ai deux contextes:
- le contexte k0s-cluster
- le contexte admin@talos-k8s-cluster
Je peux basculer d'un cluster à l'autre via la commande kubectl config use-context nom-du-contexte.
Par exemple:
lidstah@vega:~$ kubectl config use-context k0s-cluster
Switched to context "k0s-cluster".
lidstah@vega:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k0s-worker1 Ready <none> 161m v1.27.4+k0s
k0s-worker2 Ready <none> 161m v1.27.4+k0s
lidstah@vega:~$ kubectl config use-context admin@talos-k8s-cluster
Switched to context "admin@talos-k8s-cluster".
lidstah@vega:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
talos-master1 Ready control-plane 409d v1.27.4
talos-master2 Ready control-plane 89d v1.27.4
talos-master3 Ready control-plane 89d v1.27.4
talos-worker1 Ready <none> 502d v1.27.4
talos-worker2 Ready <none> 502d v1.27.4
talos-worker3 Ready <none> 502d v1.27.4
talos-worker4 Ready <none> 502d v1.27.4
talos-worker5 Ready <none> 502d v1.27.4
talos-worker6 Ready <none> 109d v1.27.4
Bien évidemment, il est important dans ce cas de bien se rappeler dans quel context on se trouve! En effet, on ne voudrait pas déployer ou détruire des charges de travail ou des éléments de configuration sur le mauvais cluster 
Pour cela, on a toujours la commande:
lidstah@vega:~$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* admin@talos-k8s-cluster talos-k8s-cluster admin@talos-k8s-cluster default
k0s-cluster k0s-cluster admin
Qui nous indique dans quel contexte nous nous trouvons. Toujours vérifier dans quel contexte on est avant de modifier quoi que ce soit!
Si vous avez la flemme ou si votre mémoire flanche - c'est humain - il est possible d'afficher le contexte dans le prompt, mais je vous laisse chercher
¶ kubectl get
La commande kubectl get suivie d'un nom de ressource, d'un namespace et optionnellement d'un nom complet de ressource permet d'obtenir des informations sur cette ressource ou la liste des ressources correspondantes. Par exemple, si je veux obtenir la liste des namespaces de mon cluster (j'y reviens en détail plus loin), il me suffit de taper:
lidstah@vega:~$ kubectl get namespaces
NAME STATUS AGE
default Active 168m
ingress-nginx Active 66m
k0s-autopilot Active 168m
kube-node-lease Active 168m
kube-public Active 168m
kube-system Active 168m
metallb-system Active 71m
Si par exemple je veux obtenir la liste des pods s'exécutant dans un namespace nommé "enterprise", il me suffit de taper la commande suivante:
lidstah@vega:~$ kubectl get pods -n enterprise
NAME READY STATUS RESTARTS AGE
bookstack-db-5fdbf4695-ws5fn 1/1 Running 0 10d
bookstack-web-5bf54b9dfb-dtvbg 1/1 Running 0 10d
dokuwiki-6879cb56d9-zfp77 1/1 Running 0 10d
doli-db-6b566566cc-5hhf4 1/1 Running 0 10d
doli-web-747446586b-bkwqr 1/1 Running 0 10d
gitea-web-b7465c7d9-42cqk 1/1 Running 0 5d10h
joplin-65899c7f74-8qwmh 1/1 Running 0 3d22h
kanboard-web-699dd7d98f-dp4mb 1/1 Running 0 5d10h
snappy-65d7f49b8-ckrf9 1/1 Running 0 10d
vault-75bf6bc7f7-4tzdg 1/1 Running 0 10d
(tiens d'ailleurs il faut que je vire mon vieux dokuwiki, je l'ai remplacé par bookstack)
¶ kubectl explain
La commande kubectl explain suivie du nom d'une ressource fournit de la documentation sur cette ressource et les éléments qui la définissent (super pratique en cas de trou de mémoire!). Par exemple, si je veux expliquer la ressource Namespace:
kubectl explain namespace
KIND: Namespace
VERSION: v1
DESCRIPTION:
Namespace provides a scope for Names. Use of multiple namespaces is
optional.
FIELDS:
apiVersion <string>
APIVersion defines the versioned schema of this representation of an object.
Servers should convert recognized schemas to the latest internal value, and
may reject unrecognized values. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources
kind <string>
Kind is a string value representing the REST resource this object
represents. Servers may infer this from the endpoint the client submits
requests to. Cannot be updated. In CamelCase. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds
metadata <ObjectMeta>
Standard object's metadata. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
spec <NamespaceSpec>
Spec defines the behavior of the Namespace. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
status <NamespaceStatus>
Status describes the current status of a Namespace. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
¶ kubectl describe
La commande kubectl describe, optionnellement suivie d'une option définissant le Namespace, suivie du nom générique d'une ressource et du nom de la ressource que l'on veut décrire, permet justement de... hum, décrire la ressource visée.
Par exemple, si je veux décrire le service réseau 'minetest-svc' situé dans l'espace de noms "games", il me suffit de taper:
lidstah@vega:~$ kubectl describe svc -n gamez minetest-svc
Name: minetest-svc
Namespace: gamez
Labels: <none>
Annotations: metallb.universe.tf/ip-allocated-from-pool: ippool
Selector: app=minetest
Type: LoadBalancer
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.101.179.194
IPs: 10.101.179.194
IP: 192.168.1.200
LoadBalancer Ingress: 192.168.1.200
Port: minetest 30000/UDP
TargetPort: 30000/UDP
NodePort: minetest 32683/UDP
Endpoints: 10.244.12.5:30000
Session Affinity: None
External Traffic Policy: Cluster
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal nodeAssigned 50s (x51 over 10d) metallb-speaker announcing from node "talos-worker6" with protocol "layer2"
Là aussi, une commande très pratique pour vérifier le bon comportement - ou pas! - d'une ressource kubernetes. Les évènements (Events) en fin de sortie permettent souvent de comprendre la cause d'un problème.
¶ kubectl create
La commande kubectl create suivie d'un type de ressource, d'une option d'espace de nom et du nom d'une ressource permet de créer rapidement une ressource (on utilisera en règle général plutôt du YAML pour ce genre de choses, mais ça peut dépanner).
Par exemple, si je veux créer, sur notre petit cluster k0s, un espace de noms nommé "pwet", il me suffit de taper:
lidstah@vega:~$ kubectl create ns pwet
namespace/pwet created
lidstah@vega:~$ kubectl get ns
NAME STATUS AGE
default Active 3h27m
ingress-nginx Active 105m
k0s-autopilot Active 3h27m
kube-node-lease Active 3h27m
kube-public Active 3h27m
kube-system Active 3h27m
metallb-system Active 109m
pwet Active 21s <<< here it is!
¶ kubectl delete
De la même façon, si je veux détruire une ressource, il me suffit d'utiliser la commande kubectl delete suivie du type de ressource, du namespace de la ressource avec l'option -n, et enfin du nom de la ressource.
Ici, nous allons détruire notre namespace "pwet":
lidstah@vega:~$ kubectl delete ns pwet
namespace "pwet" deleted
ATTENTION: ici le namespace que nous avons détruit est vide, cela n'a donc pas d'incidence, cependant, sachez que lorsqu'on détruit un namespace, on détruit tout ce qu'il contient. Je vous laisse imaginer ce que donnerai un kubectl delete ns production-qui-rapporte-des-sous dans lequel la prod' de la boite s'exécute
¶ kubectl apply
La commande kubectl apply, suivie de -f et d'un fichier yaml, permet de créer ou modifier des ressources du cluster de façon programmatique. Un fichier yaml peut contenir la définition d'une ou plusieurs ressources (par exemple, un Déploiement wordpress, un statefulset de MariaDB, ainsi que le service et l'ingress permettant de l'exposer à l'extérieur)
¶ kubectl run, exec, logs
La commande kubectl run nous permet de lancer un pod de façon arbitraire, par exemple un pod nginx dans un namespace "pwet" que nous allons recréer pour l'occasion:
kubectl create ns pwet
kubectl run -n pwet --image nginx nginx-test
kubectl get pod -n pwet
NAME READY STATUS RESTARTS AGE
nginx-test 0/1 ContainerCreating 0 6s
Au bout de quelque secondes, un nouveau kubectl get pod -n pwet devrait nous afficher:
NAME READY STATUS RESTARTS AGE
nginx-test 1/1 Running 0 78s
(sinon, on a un gros, gros problème )
Maintenant, si j'ai besoin - en général pour débugger, donc on ne fait pas ça en prod! - d'exécuter un shell dans le pod (ou plutôt dans un container du pod), je vais pouvoir le faire, quasiment de la même manière qu'avec docker ou podman, de la manière suivante:
kubectl exec -it -n pwet nginx-test -- /bin/bash
root@nginx-test:/#
# woohoo, born to be roooot!
# sortir avec un "exit"
Alors, est-ce que vous voyez la différence par rapport à Docker ou Podman?
De la même manière, je peux afficher les logs de mon pod avec la commande:
lidstah@vega:~$ kubectl logs -n pwet nginx-test
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
... et patati et patata
/docker-entrypoint.sh: Configuration complete; ready for start up
2023/08/06 21:29:32 [notice] 1#1: using the "epoll" event method
2023/08/06 21:29:32 [notice] 1#1: nginx/1.25.1
2023/08/06 21:29:32 [notice] 1#1: built by gcc 12.2.0 (Debian 12.2.0-14)
2023/08/06 21:29:32 [notice] 1#1: OS: Linux 6.1.0-10-amd64
2023/08/06 21:29:32 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 999999:999999
2023/08/06 21:29:32 [notice] 1#1: start worker processes
2023/08/06 21:29:32 [notice] 1#1: start worker process 29
2023/08/06 21:29:32 [notice] 1#1: start worker process 30
Pour le moment on va laisser "tourner" ce pod, on va en avoir besoin pour la suite!
¶ kubectl port-forward, le ssh -L sauce Kubernetes
Et le meilleur pour la fin, pour le moment notre pod nginx n'est pas exposé (heureusement) à l'extérieur. Il n'y a donc pas de moyen apparent d'y accéder. Cependant, avec la commande kubectl port-forward, je peux obtenir un résultat équivalent à un ssh -L 8080:127.0.0.1:80 user@serveurweb et accéder à mon pod nginx, s'exécutant dans mon cluster, par exemple en local, voire, l'exposer à tout le sous-réseau auquel je suis connecté ("yolo-mode"):
kubectl port-forward -n pwet pods/nginx-test 8080:80
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80
# et pour l'exposer en mode yolo:
kubectl port-forward -n pwet --address=0.0.0.0 pods/nginx-test 8080:80
Forwarding from 0.0.0.0:8080 -> 80
C'est beau (bon, c'est la page par défaut d'nginx, mais c'est beau quand même).
Allez, on va nettoyer tout ça avec un bon vieux:
lidstah@vega:~$ kubectl delete ns pwet
namespace "pwet" deleted
Il y a encore énormément de possibilités avec kubectl, un bon début pour voir tout ce qu'on peut faire avec cet utilitaire se trouve ici: https://kubernetes.io/docs/reference/kubectl/cheatsheet/
On va pouvoir commencer à écrire (beaucoup) de yaml
¶ Les objets de l'API de kubernetes
Si on a vu comment on peut manipuler les objets de Kubernetes via la commande kubectl, en règle générale on manipule nos objets via des fichiers yaml définissant ces objets. Fichiers que, bien évidemment, nous allons pouvoir versionner, et appliquer à notre cluster via la commande kubectl apply. Nous passons donc d'une gestion impérative de notre cluster via les différents outils fournis par kubectl à une gestion plus programmatique (et plus dev-friendly) des charges de travail s'exécutant sur notre cluster. De cette manière, en versionnant nos fichiers yaml décrivant l'infrastructure mise en place, il est possible de rapidement remonter un cluster, redéployer nos charges de travail tout aussi rapidement - tant que les datas utilisées par nos charges de travail sont bien là - du fait de la reproducibilité de notre environnement de travail.
Nous avons vu succintement précédemment deux objets de base de Kubernetes: les espaces de noms (Namespaces) ainsi que les Pods. On va les regarder un peu plus en détail, et ensuite on attaquera les morceaux "un peu plus gros". Vous vous doutez bien qu'on ne crée pas nos 192 pods "nginx-php-redis" à la main, quand même?
Tous les objets de l'API Kubernetes peuvent être décrits en YAML de la façon suivante:
apiVersion: version_de_l'api_REST
kind: type_de_ressource
metadata: #métadonnées de l'objet
name:
namespace:
labels:
label1: value
label2: value2
annotations:
annotation1: value
spec: #spécifications de l'objet
key: value
list:
- value1
- value2
spec: #spécification d'un objet imbriqué
env:
- name: "ENVVAR"
value: "value"
- name: "NUMERICVAR"
value: 1234
Absolument tous les objets kubernetes sont définis à partir de ce schéma.
¶ Namespaces
Un Namespace Kubernetes diffère de la notion de namespace (réseau, PID, filesystem, etc) du kernel Linux (namespaces avec lesquels sont construits nos containers du point de vue du kernel) mais a aussi quelques points communs.
Un Namespace (ou espace de noms en français) peut être considéré comme une sorte de "tiroir" dans lequel nous allons "ranger" certaines charges de travail. Imaginons que nous ayons deux clients, la COGIP et la COFRAP, pour lesquels nous mettons à disposition des ERPs dédiés (ex: Dokos, Odoo, etc). Plutôt que d'exécuter les applicatifs des deux clients en question dans le même namespace, nous allons séparer ces applicatifs dans deux namespaces dédiés à chaque client. On pourrait donc avoir un namespace "cogip" et un namespace "cofrap" dans lesquels s'exécuteront les pods ERP, base de données, cache, etc, ainsi que les Services permettant d'exposer ces services à l'extérieur et pour finir les réclamations de volumes persistants utilisés pour la persistence des données de chaque client.
Ce mécanisme permet d'isoler des ressources de différentes façons (un peu comme un LDAP/AD), soit fonctionnelle (un namespace pour les serveurs web, un autre pour les bases de données, etc), soit "nominative" (un namespace pour le client 1, un autre pour le client 2, et ainsi de suite), soit un "mix" des deux (un namespace pour les databases, puis un namespace pour les services web de chaque client).
Par défaut, les pods d'un namespace peuvent "discuter" avec les pods d'un autre namespace, mais il existe des mécanismes d'isolation (les NetworkPolicies que nous verrons ensuite) permettant de limiter le trafic réseau entre différents namespaces, voire de l'interdire complètement.
De même, il est possible de fixer des limites d'utilisation (CPU, RAM) au niveau de l'espace de noms. Par exemple, je pourrai déclarer que les charges de travail du namespace "cogip" ne peuvent utiliser au maximum que 4000 milliCPU (4 vCores) et 12Go de RAM. Cependant ce mécanisme peut avoir certains effets de bords qu'il est bon de garder en mémoire.
En bref, un Namespace nous permet d'isoler des groupes de ressources des autres groupes de ressources s'exécutant dans un autre namespace, pour peu qu'on s'en donne la peine.
Nous avons vu qu'il est trivial de créer ou supprimer un espace de noms via la commande kubectl create ns ou la commande kubectl delete ns
On peut aussi tout à fait créer un namespace depuis un fichier YAML (vim pwet.yaml):
apiVersion: v1
kind: Namespace
metadata:
name: pwet
labels:
pod-security.kubernetes.io/enforce: restricted
spec: # pas nécessaire, pas de spec pour les NS
Il nous suffit ensuite d'effectuer un simple kubectl apply -f pwet.yaml pour créer notre namespace.
Idéalement, c'est le genre de chose qu'on voudra commiter sur un dépôt git/fossil/mercurial/subversion/CVS/whatever
Un petit détail qui ne vous aura sûrement pas échappé, c'est la présence d'un label spécifique sur ce namespace: pod-security.kubernetes.io/enforce: restricted
Suivant votre cluster kubernetes, cette règle sera activée par défaut et elle implique qu'un pod s'exécutant dans cet espace de nom devra s'exécuter en mode non-privilégié (c'est à dire que tous les containers du pod doivent s'exécuter en tant qu'utilisateur non-privilégié et surtout pas en root, doit "drop" toutes les capabilities du kernel (CAP_SYSADMIN, CAP_NETWORK, etc) et ce même pour s'initialiser!). A l'inverse, la présence d'un label pod-security.kubernetes.io/enforce: privileged indique que ce qui s'exécute à l'intérieur de ce namespace est en mode yolo-root . C'est un ajout de kubernetes 1.25, plus précisément l'ajout du PodAdmissionController en remplacement de l'ancienne PodSecurityPolicy.
On reviendra sur le PodAdmissionController plus loin dans ce module. Pour le moment, si on utilise k0s ou k3s, par défaut tout s'exécute en mode yolo . A l'inverse, si on a voté pour Talos Linux, par défaut tout est en mode restreint!
ATTENTION: la destruction d'un espace de noms provoque la destruction de TOUTES les ressources qu'il contient!!!!
si si, j'insiste!
¶ Pods
On en a déjà parlé, mais le pod est en quelque sorte l'unité de base de Kubernetes. Il n'y a pas plus "petit". Un pod, on l'a vu, peut contenir plusieurs conteneurs (inception) qui pourront communiquer entre eux via un "localhost" partagé entre eux (un namespace réseau côté kernel linux).
En règle générale, on exécute rarement des pods "en solo", c'est à dire en dehors d'une unité plus grande (le ReplicaSet), elle même gérée par des objets supérieurs (Déploiements, StatefulSets, et DaemonSets) que nous verrons par la suite.
Cependant, il est là aussi possible de créer un pod solitaire depuis un fichier YAML:
apiVersion: v1
kind: Pod
metadata:
name: nginx-test
namespace: pwet
labels:
app: nginx-test
spec:
containers:
- name: nginx-test
image: nginx:latest
ports:
- name: web
containerPort: 80
protocol: TCP
Ici, la définition est extrêmement simple:
On décrit un pod nommé nginx-test, qui va s'exécuter dans le namespace pwet, qui a un seul label, "app: nginx-test", et dont la spécification défini un seul container ayant pour image "nginx:latest" (par défaut récupérée depuis le docker hub), exposant son port 80 à l'intérieur du cluster, port nommé "web" et acceptant le protocole TCP.
Bien évidemment, en règle générale nos définitions de pods seront plus complexes: on y ajoutera sûrement des points de montage pour stocker nos données, on aura peut-être plusieurs conteneurs à l'intérieur de notre pod, on ajoutera peut-être des règles de sécurité et des limites de ressources, on remplacera peut-être la ligne de commande exécutée au lancement du conteneur par une autre ("command" et "args" dans notre yaml), etc...
Nous verrons tout cela par la suite, mais pour le moment, si vous exécutez un kubectl apply -f nginx-test.yaml, vous devriez avoir un pod "nginx-test" dans le namespace "pwet".
Un dernier détail, mais les containers s'exécutant à l'intérieur d'un Pod doivent être immutables. Si vous avez besoin d'un paquet spécifique à l'intérieur de vos conteneurs, définissez le lors du build du conteneur! Il est possible de trifouiller les arguments de lancement du pod pour lui faire installer tel ou tel truc (s'il se lance en mode privilégié, beurk), mais c'est ce qu'on appelle un anti-pattern par rapport à l'esprit de Kubernetes.
¶ Note sur les initContainers d'un pod.
Un pod peut aussi avoir ce qu'on appelle un "initContainer", c'est à dire un conteneur qui va être lancé uniquement à l'initialisation du pod (par exemple, pour vérifier si le schéma en base de données est bien présent, et le créer si ce n'est pas le cas). Cependant je ne vais pas aborder tout de suite ce sujet, ça doit déjà chauffer un peu pour certain-e-s
¶ Note sur les labels et selectors (sélecteurs)
Vous l'avez remarqué, j'ai ajouté un label à notre pod. Ce n'est pas obligatoire, cependant, pour qu'un service (voyez le comme un load-balancer à la HAProxy en vraiment plus simple pour le moment) puisse trouver les pods auxquels distribuer les requêtes qu'il reçoit, il doit pouvoir les sélectionner. Cette sélection se fait à l'aide d'un sélecteur, auquel on indique le label de nos pods. Ainsi, notre service pourra "trouver" les pods auxquels distribuer les paquets IPs, segments TCP, datagrammes UDP, ou requêtes HTTP qu'il reçoit.
¶ Gestion automatisée des pods
Alors évidemment, on pourrait s'amuser à créer nos pods les uns après les autres, via des dizaines, voire des centaines de fichiers yaml, les labeliser proprement et créer un service pour les rassembler tous et sur le réseau les lier, mais ça pourrait vite devenir particulièrement pénible d'un point de vue administration du cluster. Sans compter que cela deviendrait bien évidemment excessivement error-prone. Qu'est ce qu'il se passe si j'oublie de mettre à jour l'image du pod n-1 dans son yaml? (bon, en vrai, à coup de sed -i 's/image: pwet:v1/image: pwet:v2/g' *.yaml y'a moyen que ça passe, cough cough).
Plus sérieusement, pour cela on dispose sous Kubernetes de plusieurs objets. Le premier est le ReplicaSet, qu'on utilisera quasiment - tout comme le pod - jamais directement. Il sera en général créé par un Déploiement, un StatefulSet ou un DaemonSet.
On va tout de même commencer par créer un ReplicaSet pour notre pod nginx précédent (pensez à le détruire avant). Histoire de voir comment c'est fichu
¶ ReplicaSet
Un ReplicaSet est un objet dont le seul but est de s'assurer que le bon nombre de répliques du même pod s'exécutent dans notre cluster. Si le controller-manager se rend compte que le ReplicaSet untel exécute 2 pods au lieu des 3 demandés, il en informera le serveur API qui commandera au scheduler de lancer un 3ème pod sur un worker disposant des ressources nécessaires. En règle générale, on utilisera des objets de plus haut niveau (notamment les Déploiements, Deployments) plutôt qu'un ReplicaSet directement (c'est sale :p).
Allez, soyons fous, créons notre ReplicaSet pour notre pod nginx. Et on va en coller trois ce coup ci! Créons un fichier replicaset.yaml:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
namespace: pwet
name: nginx-replica-test
labels:
app: nginx-test
spec:
replicas: 3
selector:
matchLabels:
app: nginx-test
template:
metadata:
labels:
app: nginx-test
spec:
containers:
- name: nginx-test
image: nginx:latest
ports:
- name: web
containerPort: 80
protocol: TCP
Ici, on peut remarquer un nouveau détail: le fameux selector dont je vous parlais précédemment. C'est lui qui va indiquer au ReplicaSet quel label rechercher dans nos pods, que nous créons ensuite dans notre template.
Exécutons le ensuite via un kubectl apply -f replicaset.yaml, et vérifions que notre replicaset ainsi que nos pods sont bien créés:
lidstah@vega:~/src/k0s$ kubectl get pods -n pwet
NAME READY STATUS RESTARTS AGE
nginx-replica-test-2hdzd 1/1 Running 0 12s
nginx-replica-test-7xc5q 1/1 Running 0 12s
nginx-replica-test-9gmr7 1/1 Running 0 12s
lidstah@vega:~/src/k0s$ kubectl get replicasets -n pwet
NAME DESIRED CURRENT READY AGE
nginx-replica-test 3 3 3 33s
Testons que cela fonctionne correctement avec un petit port-forward!
kubectl port-forward -n pwet rs/nginx-test-replicaset 8080:80
C'est toujours aussi moche, mais ça fonctionne. Notre ReplicaSet a simplement sélectionné le premier pod disponible pour lui envoyer notre requête!
Ainsi que nous l'avons déjà vu, le ReplicaSet est en général un objet créé par des objets de plus haut niveau.
Nous allons voir le premier d'entre eux, mais je vous laisse détruire votre ReplicaSet avant
question: quelle commande kubectl utiliserions nous pour détruire ce ReplicaSet?
¶ Déploiement
Un Déploiement (Deployment) est un objet de plus haut niveau qu'un ReplicaSet dont le but est de déclarer un état désiré des ressources qu'il décrit.
Un Déploiement peut être manipulé de façon à effectuer des mises à jour contrôlées de nos ressources (pods ici), et à pouvoir proposer des options de rollback en cas de problème. Il va générer un premier ReplicaSet lors de sa première application, puis un nouveau si l'on met à jour un élément du déploiement, et ainsi de suite. Cela va nous permettre de pouvoir rapidement revenir à un ReplicaSet antérieur en cas de souci, en revenant à la version précédente de notre Déploiement.
Dès lors, notre déploiement va fortement ressembler à un ReplicaSet, mais avec quelques modifications. Créons un fichier deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: pwet
name: nginx-deploy
labels:
app: nginx-test
spec:
replicas: 3
selector:
matchLabels:
app: nginx-test
template:
metadata:
labels:
app: nginx-test
spec:
containers:
- name: nginx-test
image: nginx:latest
ports:
- name: web
containerPort: 80
protocol: TCP
On retrouve ici, tout comme pour notre ReplicaSet, le selector qui permettra au ReplicaSet créé par notre Deployment de retrouver ses petits pods .
Regardons un peu ce que notre cluster nous a créé lorsque nous avons effectué un kubectl apply -f deployment.yaml:
lidstah@vega:~/src/k0s$ kubectl get deploy -n pwet
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deploy 3/3 3 3 7m7s
lidstah@vega:~/src/k0s$ kubectl get rs -n pwet
NAME DESIRED CURRENT READY AGE
nginx-deploy-846b6fdd9 3 3 3 7m12s
lidstah@vega:~/src/k0s$ kubectl get pods -n pwet
NAME READY STATUS RESTARTS AGE
nginx-deploy-846b6fdd9-787qp 1/1 Running 0 7m16s
nginx-deploy-846b6fdd9-wbm62 1/1 Running 0 7m16s
nginx-deploy-846b6fdd9-wtg5r 1/1 Running 0 7m16s
On voit ici que notre Déploiement a bien créé un ReplicaSet correspondant à la définition que nous en avons donné dans la spec de notre Déploiement. Ce ReplicaSet a ensuite créé trois pods nginx correspondants à la définition de ces pods renseignées dans le template de nos pods.
Modifions notre déploiement, pour par exemple passer le nombre de nos replicas à 4 au lieu de 3. Une fois ceci effectué, appliquons directement notre nouveau Déploiement (pas besoin de supprimer l'ancien), et regardons ce qu'il vient de se passer:
lidstah@vega:~/src/k0s$ kubectl get deploy -n pwet
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deploy 4/4 4 4 12m
lidstah@vega:~/src/k0s$ kubectl get rs -n pwet
NAME DESIRED CURRENT READY AGE
nginx-deploy-846b6fdd9 4 4 4 12m
lidstah@vega:~/src/k0s$ kubectl get po -n pwet
NAME READY STATUS RESTARTS AGE
nginx-deploy-846b6fdd9-787qp 1/1 Running 0 13m
nginx-deploy-846b6fdd9-7fvtf 1/1 Running 0 34s
nginx-deploy-846b6fdd9-wbm62 1/1 Running 0 13m
nginx-deploy-846b6fdd9-wtg5r 1/1 Running 0 13m
Ici, comme notre Déploiement ne fait que modifier un ReplicaSet existant pour augmenter le nombre de pods exécutant notre conteneur, rien de spécial.
Modifions maintenant l'image utilisée par notre Déploiement. On va utiliser nginx:stable-alpine au lieu de nginx:latest, et appliquer notre YAML après modification, et enfin regarder ce qu'il se passe du côté du ReplicaSet en spammant kubectl get rs -n pwet:
lidstah@vega:~/src/k0s$ kubectl apply -f deployment.yaml
deployment.apps/nginx-deploy configured
lidstah@vega:~/src/k0s$ kubectl get rs -n pwet
NAME DESIRED CURRENT READY AGE
nginx-deploy-5467d68df9 1 1 0 4s
nginx-deploy-846b6fdd9 3 3 3 18m
lidstah@vega:~/src/k0s$ kubectl get rs -n pwet
NAME DESIRED CURRENT READY AGE
nginx-deploy-5467d68df9 2 2 1 9s
nginx-deploy-846b6fdd9 2 2 2 18m
lidstah@vega:~/src/k0s$ kubectl get rs -n pwet
NAME DESIRED CURRENT READY AGE
nginx-deploy-5467d68df9 2 2 1 11s
nginx-deploy-846b6fdd9 2 2 2 18m
lidstah@vega:~/src/k0s$ kubectl get rs -n pwet
NAME DESIRED CURRENT READY AGE
nginx-deploy-5467d68df9 3 3 2 13s
nginx-deploy-846b6fdd9 1 1 1 18m
lidstah@vega:~/src/k0s$ kubectl get rs -n pwet
NAME DESIRED CURRENT READY AGE
nginx-deploy-5467d68df9 3 3 3 15s
nginx-deploy-846b6fdd9 0 0 0 18m
Ici, notre Déploiement modifié a créé un nouveau ReplicaSet. Et progressivement remplacé les pods par de nouveaux pods avec la nouvelle image. Mmmmh, c'est intéressant ça, il n'a pas tué tous les pods d'un coup pour en popper de nouveau. Non, il a effectué la migration pod par pod (c'est le comportement par défaut).
Bien sûr, on peut dimensionner "à l'arrache" un déploiement via kubectl, dans notre cas:
lidstah@vega:~/src/k0s$ kubectl scale deployment -n pwet nginx-deploy --replicas 6
deployment.apps/nginx-deploy scaled
lidstah@vega:~/src/k0s$ kubectl get deploy,pod -n pwet
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx-deploy 4/6 6 4 38s
NAME READY STATUS RESTARTS AGE
pod/nginx-deploy-846b6fdd9-d5jt4 1/1 Running 0 38s
pod/nginx-deploy-846b6fdd9-fkjzz 1/1 Running 0 2s
pod/nginx-deploy-846b6fdd9-fqf9d 0/1 ContainerCreating 0 2s
pod/nginx-deploy-846b6fdd9-l5grb 1/1 Running 0 38s
pod/nginx-deploy-846b6fdd9-rrfs7 1/1 Running 0 38s
pod/nginx-deploy-846b6fdd9-zf7q7 0/1 ContainerCreating 0 2s
On peut aussi automatiser le dimensionnement de notre Déploiement via un Horizontal Pod Autoscaler (HPA), afin que notre déploiement crée automatiquement de nouveaux pods si la charge CPU des pods existants, par exemple, dépasse un certain seuil. Bon là c'est un peu en dehors de notre périmètre, et attention aux effets de bord (il ne faudrait pas "affamer" (starve) les ressources d'autres charges de travail).
Ce qui nous amène à un élément très, très sympa des Déploiements: le RollingUpdate et ses paramètres qui vont nous permettre de gérer la mise à jour de nos pods lorsque nous modifions notre déploiement.
Cependant, est-ce que vous ne voyez pas déjà arriver un problème avec les bases de données, qui vont utiliser des volumes persistants. Qu'est-ce qu'il se passe si deux bases de données utilisent les mêmes fichiers? Il se passe ça:

Ceci dit on évite d'utiliser des Déploiements pour des bases de données, on leur préfèrera le StatefulSet, c'est en général une mauvaise idée d'utiliser un Déploiement pour une base de données.
Ce qui m'amène à la gestion des mises à jour de notre Déploiement, les RollingUpdates (ou pas!)
¶ RollingUpdates ooow yeah!
Une Rolling Update nous permet de mettre à jour les pods d'un déploiement sans aucune coupure du service. En effet, suivant les paramètres que nous allons utiliser, il y aura toujours au moins un pod (ou plus) disponible pour répondre aux requêtes des utilisateurs. Le Service (on va voir ça plus en détail dans la partie réseau), lui, va distribuer les requêtes utilisateurs uniquement aux pods fonctionnels. Ainsi, notre applicatif reste toujours disponible, même lorsqu'on le met à jour.
Côté YAML, on peut modifier le comportement des RollingUpdates d'un Déploiement dans la spec de ce déploiement:
spec:
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: X
maxUnavailable: Y
Ici, on définit une stratégie de mise à jour de notre déploiement autorisant Y Pods indisponibles et X pods "en plus" de notre nombre de réplicas initialement demandé (pendant la transition). On peut utiliser un nombre arbitraire, ou des pourcentages pour cette valeur (par exemple, je pourrai avoir maxSurge: 50% qui m'autorisera à avoir 50% de pods en plus par rapport à mon nombre de réplicas désirés pendant la mise à jour)
Par exemple, si j'ai une valeur de replicas: 10, maxSurge: 5, maxUnavailable: 1, alors je pourrai avoir jusqu'à 15 pods pendant ma mise à jour, avec un seul pod de l'ancien ReplicaSet stoppé à la fois.
Les valeurs par défaut sont de 25% pour maxSurge et maxUnavailable.
A noter: Si jamais vous utilisez un Déploiement pour une base de données ("shame, shame, shame"), on voudra privilégier une stratégie de type Recreate et non RollingUpdate. Ainsi notre base de données sera stoppée proprement avant d'être relancée avec sa nouvelle image de conteneur, et on évite tout potentiel problème où deux pods voudraient accéder aux fichiers de notre précieuse BDD en même temps. Et faire des vilains chocapics avec vos données dans la foulée.
¶ RollBack (aka j'ai tout cassé aidez moi)
En théorie, avec Kubernetes, quand on a cassé un déploiement, il se passe ça:

En effet, en théorie, on peut rollback notre Déploiement facilement - tant qu'il est parfaitement stateless!!
Revenons à notre Déploiement, et essayons de le rétablir à une version antérieure. Tout d'abord nous allons vérifier l'historique de notre déploiement:
lidstah@vega:~/src/k0s$ kubectl rollout history -n pwet deployment/nginx-deploy
deployment.apps/nginx-deploy
REVISION CHANGE-CAUSE
1 <none>
2 <none>
mmh, ce <none> est embêtant... En effet, nous aurions dû ajouter une annotation à notre déploiement que nous aurions modifié à chaque itération, pour bien faire les choses.
Ceci dit, dans notre cas, il est trivial de revenir à notre ancien déploiement: c'est tout simplement la révision de plus faible identifiant numérique.
(mais j'insiste: pensez à annoter vos déploiements dans le milieu professionnel - et en règle générale votre annotation correspondra au début de votre message de commit - je dis ça comme ça hein mais vous n'imaginez pas comment ça peut être pénible de débugger l'environnement de dev' d'un collaborateur qui n'annote pas ses déploiements... "mmmh, la révision 12, elle date de quel commit dans ta branche?". que du bonheur.)
Regardons une révision de plus près:
lidstah@vega:~/src/k0s$ kubectl rollout history -n pwet deployment/nginx-deploy --revision=2
deployment.apps/nginx-deploy with revision #2
Pod Template:
Labels: app=nginx-test
pod-template-hash=86785c478f
Containers:
nginx-test:
Image: nginx:stable-alpine
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Ah oui, c'est là qu'on est passés à l'image nginx:stable-alpine. La révision #1 doit donc utiliser l'image nginx:latest. Allez, rollbackons notre déploiement vers sa première révision!
lidstah@vega:~/src/k0s$ kubectl rollout undo -n pwet deployment/nginx-deploy --to-revision=1
deployment.apps/nginx-deploy rolled back
et vérifions rapidement avec un kubectl describe de notre déploiement que l'image utilisée par nos pods est bien nginx:latest! Quelle commande utiliseriez-vous - et pensez à grep parceque c'est verbeux hein, la preuve:
lidstah@vega:~/src/k0s$ kubectl describe deployments.apps -n pwet nginx-deploy
Name: nginx-deploy
Namespace: pwet
CreationTimestamp: Tue, 08 Aug 2023 00:59:05 +0200
Labels: app=nginx-test
Annotations: deployment.kubernetes.io/revision: 4
Selector: app=nginx-test
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx-test
Containers:
nginx-test:
Image: nginx:latest
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: nginx-deploy-86785c478f (0/0 replicas created)
NewReplicaSet: nginx-deploy-7b54d68655 (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 22m deployment-controller Scaled up replica set nginx-deploy-86785c478f to 3
Normal ScalingReplicaSet 21m deployment-controller Scaled up replica set nginx-deploy-7b54d68655 to 1
Normal ScalingReplicaSet 21m deployment-controller Scaled down replica set nginx-deploy-86785c478f to 1 from 2
Normal ScalingReplicaSet 21m deployment-controller Scaled up replica set nginx-deploy-7b54d68655 to 3 from 2
Normal ScalingReplicaSet 21m deployment-controller Scaled down replica set nginx-deploy-86785c478f to 0 from 1
Normal ScalingReplicaSet 7m9s deployment-controller Scaled up replica set nginx-deploy-86785c478f to 1 from 0
Normal ScalingReplicaSet 7m7s deployment-controller Scaled up replica set nginx-deploy-86785c478f to 2 from 1
Normal ScalingReplicaSet 7m7s deployment-controller Scaled down replica set nginx-deploy-7b54d68655 to 2 from 3
Normal ScalingReplicaSet 7m6s deployment-controller Scaled down replica set nginx-deploy-7b54d68655 to 1 from 2
Normal ScalingReplicaSet 7m6s deployment-controller Scaled up replica set nginx-deploy-86785c478f to 3 from 2
Normal ScalingReplicaSet 7m5s deployment-controller Scaled down replica set nginx-deploy-7b54d68655 to 0 from 1
Normal ScalingReplicaSet 64s deployment-controller Scaled up replica set nginx-deploy-7b54d68655 to 1 from 0
Normal ScalingReplicaSet 62s (x2 over 21m) deployment-controller Scaled up replica set nginx-deploy-7b54d68655 to 2 from 1
Normal ScalingReplicaSet 62s (x2 over 21m) deployment-controller Scaled down replica set nginx-deploy-86785c478f to 2 from 3
Normal ScalingReplicaSet 60s (x3 over 61s) deployment-controller (combined from similar events): Scaled down replica set nginx-deploy-86785c478f to 0 from 1
Avouez que c'est quand même bien foutu, non?
¶ StatefulSet
Avant d'attaquer les StatefulSets, il va être nécessaire de faire un petit détour par le Storage. En effet pour le moment, tout ce que nous avons fait est purement stateless. Nous ne stockons pas de données autres que temporaires, et nous n'avons pas abordé le problème de la persistence des données. On va se servir de notre VM NFS, finalement
Maintenant qu'on a joué avec Helm et installé nfs-subdir-external-provisioner avec Helm, et vérifié que ce déploiement nous avait ajouté une classe de stockage (StorageClass) nommée nfs-client, on va pouvoir regarder de plus près ce qu'est un Statefulset!
Un Statefulset, c'est un objet Kubernetes semblable au déploiement, qui va donc gérer la création, la réplication, la mise à jour de Pods, mais de pods avec états (stateful). C'est à dire de pods qui vont stocker des données qui ne doivent pas être partagées entre eux. Comme par exemple une base de données Postgresql avec deux pods, un master et un replica (ou plusieurs replica). Si les données que ces pods utilisent sont - sensiblement - identiques, chaque pod doit disposer de son propre espace de stockage dédié pour stocker ces données.
Un StatefulSet crée donc des pods:
- uniques et ayant toujours le même nom
- ayant toujours le même nom DNS
- un stockage persistant stable
- un contrôle du déploiement, de la mise à jour et des RollingUpdates bien précis
- La suppression d'un StatefulSet ne détruit pas le storage persistant auquel il était lié. Data First©
- Un StatefulSet nécessite obligatoirement la création d'un Service Headless, sans adresse IP dans le cluster ou à l'extérieur.
On va se créer un premier StatefulSet avec, au hasard, une bonne vieille MariaDB, histoire de changer. On va se créer un Namespace dédié à notre bdd, qu'on va appeler "maria" (ou tout autre nom, si vous voulez l'appeler pwet... mais dans ce cas adaptez )
apiVersion: v1
kind: Service
metadata:
name: maria-svc
namespace: maria
labels:
app: mariadb-test
spec:
ports:
- port: 3306
name: mariadb
protocol: TCP
clusterIP: None
selector:
app: mariadb-test
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mariadb-test
namespace: maria
spec:
selector:
matchLabels:
app: mariadb-test
serviceName: "maria-svc"
replicas: 1
template:
metadata:
labels:
app: mariadb-test
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mariadb
image: mariadb:10.5
env:
- name: "MARIADB_ROOT_PASSWORD"
value: "epsiepsi"
- name: "MARIADB_DATABASE"
value: "epsi"
- name: "MARIADB_PASSWORD"
value: "epsiepsi"
- name: "MARIADB_USER"
value: "epsi"
ports:
- containerPort: 3306
name: mariadb
protocol: TCP
volumeMounts:
- name: maria
mountPath: /var/lib/mysql
volumeClaimTemplates:
- metadata:
name: maria
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs-client"
resources:
requests:
storage: 2Gi
Vérifions que tout est bien lancé:
lidstah@vega:~/src/k0s$ kubectl get sts -n maria
NAME READY AGE
mariadb-test 1/1 2m32s
lidstah@vega:~/src/k0s$ kubectl get svc -n maria
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
maria-svc ClusterIP None <none> 3306/TCP 2m38s
lidstah@vega:~/src/k0s$ kubectl get pod -n maria
NAME READY STATUS RESTARTS AGE
mariadb-test-0 1/1 Running 0 2m44s
lidstah@vega:~/src/k0s$ kubectl get pvc -n maria
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
maria-mariadb-test-0 Bound pvc-0d1621ea-e721-411a-ad3a-bf19dc726de1 2Gi RWO nfs-client 2m49s
Seems legit
Testons si nous pouvons accéder à notre base de données via un kubectl port-forward que je vous laisse taper
Normalement, si on a le client mysql (ou tout autre client mysql, graphique ou pas), nous devrions pouvoir nous connecter à notre base de donnée en local via un mysql -h127.0.0.1 -uroot -pepsiepsi
Ce qui devrait nous donner ça:
It works!©
Par contre, nous avons maintenant un petit problème de sécurité concernant les identifiants de notre base de données, le voyez-vous dans le YAML que nous venons de créer? (hormis les mots de passe pourris, of course).
Ce problème est aussi présent sur un kubectl describe de notre StatefulSet:
lidstah@vega:~/src/k0s$ kubectl describe sts -n maria mariadb-test
Name: mariadb-test
Namespace: maria
[snip]
Update Strategy: RollingUpdate
Partition: 0
Pods Status: 1 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=mariadb-test
Containers:
mariadb:
Image: mariadb:10.5
Port: 3306/TCP
Host Port: 0/TCP
Environment:
MARIADB_ROOT_PASSWORD: epsiepsi
MARIADB_DATABASE: epsi
MARIADB_PASSWORD: epsiepsi
MARIADB_USER: epsi
Mounts:
/var/lib/mysql from maria (rw)
Volumes: <none>
[snip]
Nous verrons comment remédier à ce problème dans la partie Sécurité, et notamment la partie concernant les Secrets Kubernetes.
¶ DaemonSet
Un DaemonSet est une sorte de déploiement qui va déployer un pod et un seul sur chaque worker de notre cluster. En gros, si je crée un DaemonSet nginx, il va me déployer un pod nginx sur chaque worker de mon cluster.
L'utilité peut sembler minimale, mais en fait c'est assez utilisé notamment par:
- Les LoadBalancers type MetalLB qui vont exécuter un "speaker" par noeud
- Les outils de collecte de métriques ou logs comme Prometheus, ECK fluentd, etc
- Les outils de stockage (StorageClasses) utilisant le stockage local des noeuds du cluster comme LongHorn, Piraeus Datastore (basé sur Linstor), Rook Ceph...
- Et plus généralement tous les outils bas niveau ayant besoin de s'exécuter sur chaque node du cluster.
La syntaxe est identique à celle d'un Deployment à l'exception du paramètre kind qui aura pour valeur, et bien évidemment, le paramètre replicas ne s'applique pas vu qu'il n'a aucun sens dans ce contexte :
kind: DaemonSet
¶ Ressources: Requests et Limits
Bien évidemment, via les cgroups (Control Groups) du Kernel Linux, nous pouvons assigner des ressources CPU et mémoire minimales (requests) et maximales (limits) à nos pods (et donc, aux pods générés par nos Déploiements, StatefulSets et Daemonsets), afin d'être sûr qu'un pod disposera toujours des ressources minimales nécessaires à son fonctionnement, ou qu'il ne dépassera jamais certaines limites CPU et RAM afin de ne pas "paralyser" d'autres pods s'exécutant sur le même noeud de notre Cluster.
Les requêtes comme les limites sont des ressources réservées c'est à dire qu'elles vont déterminer si d'autres pods vont pouvoir être exécutés sur un noeud du cluster ou pas, il est donc important de bien dimensionner ces paramètres afin d'éviter des effets de bords désagréables (par exemple, avoir des requêtes ou des limites trop élevées, qui ne seront jamais utilisées par le pod mais qui empêchent d'assigner d'autres charges de travail sur le ou les noeuds du cluster concernés).
En règle générale, si on utilisera souvent les requests pour déterminer les ressources minimales à l'exécution d'un pod, on évitera d'utiliser les limites sauf cas spéciaux (notamment applicatif avec fuite de mémoire).
Par exemple, si on veut assigner à notre déploiement nginx-test précédent des ressources de ce type:
- requests: 10 millicpu (1%) et 32Mo de RAM
- limites: 50 millicpu (5%) et 64Mo de RAM
On modifiera notre déploiement de la sorte:
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: pwet
name: nginx-deploy
labels:
app: nginx-test
spec:
replicas: 3
selector:
matchLabels:
app: nginx-test
template:
metadata:
labels:
app: nginx-test
spec:
containers:
- name: nginx-test
image: nginx:latest
ports:
- name: web
containerPort: 80
protocol: TCP
resources:
requests:
cpu: "10m"
memory: "32Mi"
limits:
cpu: "50m"
memory: "64Mi"
¶ Réseau
Il y a plusieurs réseaux à l'intérieur d'un cluster Kubernetes:
- Le réseau interne d'un pod, entre les containers (~ localhost).
- Le réseau des Pods eux-mêmes, dépendant de la CNI utilisée. Flannel, par exemple, utilise 10.244.0.0/16, Weave net (de mémoire) 10.32.0.0/12, etc. Habituellement, on peut configurer ce sous-réseau dans la configuration de la CNI, sauf pour Flannel.
- Le réseau des Services, là aussi géré par la CNI, mais en général on retrouve souvent 10.96.0.0/12.
- Le réseau externe du cluster, c'est à dire le réseau (idéalement) privé où les nodes communiquent entre eux.
- Et enfin le réseau "public" assigné au Load-Balancer (cela peut aller d'une adresse IP unique à un ou plusieurs intervalles d'adresses voire plusieurs blocs, et il peut se trouver, ou pas, dans le même bloc que le réseau de communication des nodes).
Pour que les pods et services puissent discuter entre eux d'un node à l'autre, les réseaux internes du cluster sont généralement encapsulés dans des VxLANs (en gros, du VLAN over UDP - ce qui explique la différence de MTU entre un lien interne et la MTU des nodes), mais on peut trouver d'autres solutions (VLANs classiques dédiés par exemple).
¶ DNS
Tout Pod, Service dispose de son enregistrement DNS "personnel". En effet, un même pod peut changer d'adresse IP entre deux versions d'un déploiement, un service peut changer d'IP si on le modifie ou si on redémarre le cluster, alors qu'ils auront toujours le même nom DNS.
En règle générale, Kubernetes utilise CoreDNS (2 pods sont normalement créés) comme serveur DNS interne. Le nom de domaine du cluster, défini à sa création, est par défaut "cluster.local".
Un pod "nginx" dans un espace de noms "web" aura pour FQDN nginx.web.pod.cluster.local., et un service "nginx-svc" dans le même espace de nom aura pour FQDN nginx-svc.web.svc.cluster.local..
On peut modifier les paramètres DNS d'un pod. Par défaut, un pod effectuera ses recherches DNS d'abord via CoreDNS (le DNS interne de kubernetes), puis via le ou les serveurs DNS définis sur l'hôte. C'est la politique DNS ClusterFirst.
Il en existe 4:
- Default: ce n'est pas la politique par défaut . Dans ce cas, le pod utilisera uniquement la résolution DNS du noeud sur lequel il s'exécute
- ClusterFirst: Toute résolution DNS qui ne contient pas le domaine du cluster (cluster.local dans notre cas), utilisera les serveurs DNS configurés sur l'hôte. C'est la configuration par défaut
- ClusterFirstWithHostNet: uniquement pour les pods (privilégiés) qui utilisent le réseau de l'hôte sur lesquels ils s'exécutent (hostNetwork)
- None: On fournit nous même la configuration DNS du pod dans un champ
dnsConfigde sa spec'.
Exemple avec une dnsPolicy "None" et en configurant nous mêmes les serveurs DNS utilisés par le pod:
spec:
dnsPolicy: "None"
dnsConfig:
nameservers:
- 192.168.1.1
searches:
- bidule.com
- bidule.net
options:
- name: ndots
value: "5"
- name: edns0
containers:
- name: nginx
image: nginx:v1.22.0
[... suite habituelle ...]
¶ Services
Pour le moment, nous n'avons rien exposé à l'extérieur de notre cluster. Ni même, en réalité, à l'intérieur de notre cluster. Nous avons pu accéder à nos applicatifs de tests via la commande kubectl port-forward, qui, si elle est très pratique pour débugger, tester, etc, ne nous permettrait pas d'exposer des services à l'extérieur de façon fiable (on pourrait imaginer un kubectl port-forward sur une machine faisant tourner haproxy ou autre load-balancer, mais il vaut mieux que cela reste du domaine de l'imaginaire ).
Pour exposer nos services, soit à l'intérieur, soit à l'extérieur du cluster, Kubernetes dispose d'un objet appelé... Service . Il fonctionne un peu comme un Load-Balancer. Si j'ai un déploiement avec 3 pods, par exemple, et un Service lié à ce Déploiement, exposé à l'intérieur du cluster avec le FQDN nginx-svc.pwet.svc.cluster.local et écoutant sur le port 80, alors tout pod du cluster (minus NetworkPolicy), peut accéder à ce service (et donc aux pods derrière).
Pour "trouver" les pods où envoyer les requêtes qu'il reçoit, un Service utilise un sélecteur (selector), en général pointant un label présent dans la définition des pods que l'on veut atteindre via ce Service, et un ou plusieurs ports sur lesquels écouter, ainsi que des ports cible (targerPort) où envoyer ce qui est reçu sur le port d'écoute du service.
Un template YAML de Service (ici de type ClusterIP) ressemble donc généralement à ça:
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: pwet
spec:
type: ClusterIP # ou autre, cf plus bas
selector:
app: nginx-test
ports:
- name: web
port: 80
targetPort: 80
protocol: TCP
- name: https
port: 443
targetPort: 443
protocol: TCP
¶ Services de type ClusterIP
C'est le type de service par défaut. Il attribue au Service une adresse IP dans le réseau interne du cluster dédié aux services. On peut préciser cette adresse manuellement (mais bien sûr il ne faut pas utiliser une IP déjà attribuée ), mais en général il est mieux de laisser le cluster décider.
On utilise en général ce type de service pour exposer des applicatifs de façon interne au cluster, applicatifs que nous ne voulons pas exposer à l'extérieur (exemple: bases de données, cache (redis, varnish, etc)).
¶ Services de type LoadBalancer et installation de MetalLB
Le but d'un LoadBalancer est d'assigner une (ou plusieurs) IP "publique" (i.e extérieure aux réseaux internes de Kubernetes et donc joignable de l'extérieure) à un Service, afin de pouvoir y accéder sans utiliser le port-forwarding de kubectl.
En règle générale, votre fournisseur de solution cloud vous proposera un Load-Balancer "maison" bien évidemment payante (ou gratuite pour la première IP publique, auquel cas un Ingress s'imposera rapidement ).
MetalLB, lui, est un load-balancer dédié aux installations baremetal de Kubernetes. Il en existe d'autres, par exemple svc-lb utilisé par k3s (qui assigne à chaque service les IPs des nodes composant le cluster. Ce qui veut dire que l'on ne peut avoir qu'un service écoutant sur un port donné (ex: 8080)), les ports 80 et 443 étant déjà réservés pour l'Ingress de k3s (Traefik). L'avantage de MetalLB ici, est qu'on peut définir un ou plusieurs pools d'adresses IPs (liste d'adresses IP, bloc (/24, /16, etc), ou intervalle (192.168.100.10 - 192.168.100.50)) à assigner soit manuellement soit automatiquement à nos Services.
Il est capable d'annoncer les adresses assignées à nos Services soit en L2 OSI via ARP, soit en L3 OSI via BGP (classe!).
Son installation peut se faire soit via Helm (qu'on verra plus tard), soit directement via un fichier YAML téléchargeable sur le site de metalLB: https://metallb.universe.tf/ pour le site et la documentation, et https://raw.githubusercontent.com/metallb/metallb/v0.13.10/config/manifests/metallb-native.yaml pour la version actuelle. Un simple wget du YAML suivi d'un kubectl apply -f du fichier téléchargé suffira à l'installer sur un cluster Kubernetes on-prem.
Il est composé de deux éléments installés par défaut dans le Namespace metallb-system:
- Un Déploiement, controller, qui s'occupe d'assigner les adresses IPs aux Services qui le demandent
- Un Daemonset, speaker, qui tourne donc sur tous les noeuds de notre cluster et dont le rôle est d'annoncer au "monde extérieur" soit via ARP soit via BGP les adresses IPs assignées aux Services par le controller.
On le verra dans la partie Sécurité et notamment RBAC, mais l'installation de metalLB crée aussi les comptes de service (serviceaccounts) nécessaires à la modification des configurations réseau et iptables des nodes, et l'ensemble s'exécute en mode privilégié avec les Capabilities du Kernel permettant la manipulation de la pile réseau du noyau Linux.
On va vouloir ensuite configurer deux choses:
- Nos pools d'adresse IP
- Le mode d'annonce (ARP ou BGP) de ces pools d'IPs. En effet, on peut tout à fait annoncer des pools d'adresses IP différents de façons différentes, par exemple un premier pool en BGP, et le second pool d'adresses via ARP!
Imaginons que je veuille pouvoir assigner (indifféremment - metalLB prendra la première adresse disponible si on ne précise pas manuellement l'IP à assigner au service) des IPs des blocs et intervalles suivants via metalLB, en ARP:
- 172.16.250.0/24
- 192.168.100.50 à 192.168.100.60
Mon fichier YAML définissant ces deux ressources (les pools et l'annonce) aura donc pour forme:
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: ippoolL2
namespace: metallb-system
spec:
addresses:
- 172.16.250.0/24
- 192.168.100.50-192.168.100.60
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: ippool-l2-advertisement
namespace: metallb-system
spec:
ipAddressPools:
- ippoolL2
Il me suffit donc d'appliquer via kubectl apply -f ce fichier YAML pour créer mes pools d'adresses IP et leur annonce sur le réseau "public".
À partir de ce moment, je peux assigner une IP "publique" à mes Services de type LoadBalancer. Si je reprends mon fichier YAML précédent définissant un Service de type ClusterIP et que je le modifie pour assigner l'IP 192.168.100.55 à mon service nginx-svc:
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: pwet
spec:
type: LoadBalancer
loadBalancerIP: 192.168.100.55
selector:
app: nginx-test
ports:
- name: web
port: 80
targetPort: 80
protocol: TCP
- name: https
port: 443
targetPort: 443
protocol: TCP
Je devrais pouvoir accéder à mon service nginx-svc (puis aux pods labellés "nginx-test" écoutant derrière) via les ports 80 et 443, à l'adresse IP 192.168.100.55 (pour autant que j'ai accès à ce sous-réseau soit directement, soit via un routeur).
Évidemment, si j'ai plusieurs services que je veux exposer à l'extérieur via cette méthode, il faut que j'utilise plusieurs adresses IPs "publiques", ce qui peut être rédhibitoire notamment si on utilise de vraies adresses IP publiques (ça coûte cher), ou si on utilise un cluster "dans le cloud" (ça coûte encore plus cher!). Cependant sur un réseau RFC1918 dont on a le contrôle, cela peut permettre une grande flexibilité. Et si on veut ensuite accéder à ces services depuis l'extérieur (Internet, autre réseau interne, etc), il suffit d'utiliser une VM load-balancer/reverse-proxy avec par exemple HAProxy ou Nginx (qui pourront dans la foulée s'occuper de la terminaison TLS pour de l'HTTPS).
Par contre, si pour diverses raisons on ne dispose que d'un nombre restreint d'adresses IPs "publiques" (voire une seule) et/ou si on veut terminer la liaison TLS à l'entrée de notre cluster, assigner cette IP (via notre LoadBalancer) à un service d'Ingress sera plus pertinent.
¶ Services de type NodePort (don't use them!)
Si on a pas d'autre possibilité, on peut aussi utiliser le Service de type NodePort pour rendre nos Services joignables de l'extérieur. Par défaut, Kubernetes assigne la plage de ports 30000 à 32767 à ces Services, qui deviennent joignables à l'IP:Port de chaque noeud de notre cluster.
Par exemple:
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: pwet
spec:
type: NodePort
selector:
app: nginx-test
ports:
- name: web
port: 80
targetPort: 80
protocol: TCP
nodePort: 30010
Ici, je pourrai accéder à mes pods nginx via mon Service de type NodePort depuis les adresses IPs de chaque membre de mon cluster, au port 30010.
Cependant, il est en général considéré comme une mauvaise pratique d'utiliser NodePort en production:
- Un seul port par service
- Si les IPs de mes noeuds changent (ajout/suppression/etc) je devrais probablement reconfigurer d'autres services (haproxy, caches web, etc) en amont, ce qui contredit un peu les objectifs de Kubernetes.
- Par défaut je suis limité à 2768 ports, soit 2768 services.
- D'un point de vue sécurité, il est bon d'isoler les communications du cluster (API, VxLANs, Storage, etc) des points d'entrée des utilisateurs.
¶ EndPointSlices
Un EndPointSlice contient les références d'un ensemble d'endpoints (en général, les ClusterIPs des pods d'un même déploiement lié à un Service). C'est un objet créé automatiquement par le cluster Kubernetes. Par exemple:
lidstah@vega:~/src/k0s$ kubectl get endpointslices -n maria
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
maria-svc-9szg4 IPv4 3306 10.244.1.12 87s
# un petit describe?
lidstah@vega:~/src/k0s$ kubectl describe endpointslices -n maria maria-svc-9szg4
Name: maria-svc-9szg4
Namespace: maria
Labels: app=mariadb-test
endpointslice.kubernetes.io/managed-by=endpointslice-controller.k8s.io
kubernetes.io/service-name=maria-svc
service.kubernetes.io/headless=
Annotations: endpoints.kubernetes.io/last-change-trigger-time: 2023-08-11T16:16:42Z
AddressType: IPv4
Ports:
Name Port Protocol
---- ---- --------
mariadb 3306 TCP
Endpoints:
- Addresses: 10.244.1.12
Conditions:
Ready: true
Hostname: mariadb-test-0
TargetRef: Pod/mariadb-test-0
NodeName: k0s-worker2
Zone: <unset>
Events: <none>
¶ Ingress
Un Ingress en terminologie Kubernetes, se comporte comme les reverse-proxies que l'on connaît bien (Nginx, HAproxy, Traefik, etc). La majorité des Ingresses disponibles sont d'ailleurs basés sur des reverses proxies connus:
- Ingress-nginx sur Nginx
- traefik-ingress basé sur... Traefik
- Haproxy ingress controller basé sur ... Haproxy. Version communautaire et version Entreprise
- Voyager, basé sur HAProxy avec en prime génération et renouvellement automatiques de certificats Let's Encrypt. Payant.
Un des Ingresses les plus utilisés étant ingress-nginx, c'est ce que nous allons utiliser.
Un Ingress, par défaut, utilisera le Header Host des requêtes de l'utilisateur pour déterminer à quels services internes (et donc quels pods) envoyer le trafic qu'il reçoit. Par exemple:
- Les requêtes à l'intention de nginx.domain.tld seront envoyées au Service interne (ClusterIP) nginx-svc, qui les enverra aux pods appartenant à ce Service via le selector et les labels des pods.
- Les requêtes à l'intention de gitea.domain.tld seront envoyées au Service Gitea, qui les enverra aux pods exécutant Gitea.
- et ainsi de suite.
Si on ne dispose pas d'enregistrements DNS/ de serveur DNS, on peut utiliser notre fichier hosts (UNIX et Linux: /etc/hosts, Windows: C:\Windows\System32\drivers\etc\hosts) pour établir la corrélation IP <-> FQDN, par exemple:
192.168.100.55 nginx.mondomaine.com
¶ Installation
L'installation est là aussi très simple, soit on utilise Helm, soit on utilise le YAML officiel d'ingress-nginx:
- Documentation: https://kubernetes.github.io/ingress-nginx/deploy/
- YAML de déploiement: https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.1/deploy/static/provider/cloud/deploy.yaml
Le YAML va créer les différentes ressources nécessaires au fonctionnement d'ingress-nginx, parmi lesquelles:
- Un namespace ingress-nginx.
- Un déploiement pour le contrôleur d'ingress-nginx dans ce même Namespace.
- Un service de type LoadBalancer, auquel MetalLB devrait avoir assigné la première IP disponible.
¶ Exemple: exposer nginx-svc via notre ingress
Reprenons notre service "nginx-svc" (de type ClusterIP) dans son namespace "pwet", pointant vers les pods créés par notre Déploiement "nginx-test". Nous voulons l'exposer via notre Ingress, et y accéder depuis le FQDN nginx.mondomaine.com (cf enregistrement hosts plus haut).
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-nginx
namespace: pwet
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
# je mets la configuration TLS pour l'exemple
tls:
- hosts:
- nginx.mondomaine.com
secretName: mon-secret-tls
# règles de routage:
rules:
- host: nginx.mondomaine.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx-svc
port:
number: 80
Les règles tls sont ici données pour l'exemple. On peut utiliser cert-managerpour générer automatiquement des certificats auto-signés, ou via Let's Encrypt, ou on peut fournir manuellement à ingress-nginx un Secret de type TLS contenant notre certificat et sa clef privée afin qu'il l'utilise pour accéder à notre ressource en https. De plus, il effectue la redirection 3xx automatiquement. Si on dispose d'un certificat de type wildcard, on peut l'utiliser comme certificat par défaut en modifiant le déploiement d'ingress-nginx et en ajoutant la ligne dans les arguments du pod:
--default-ssl-certificate=namespace/mon-certificat-wildcard
Pour indiquer à Ingress-nginx d'utiliser le secret "mon-certificat-wildcard" se trouvant dans l'espace de noms "namespace" si je ne fournis pas de certificat dans la définition de mon Ingress.
Ici, on voit que mes metadonnées ont un champ annotations, qui détermine la classe de mon Ingress. Je pourrai aussi ajouter à ces annotations des paramètres propres à nginx (CORS, taille d'upload maximale, etc).
Bien évidemment, si j'ai plusieurs services dans le même namespace que je voudrais exposer avec mon Ingress, je peux simplement les ajouter à la liste "rules".
Je peux aussi jouer sur le "Path". Par exemple "/" m'enverrai vers mon service "nginx-svc" et un path "/login" m'enverrai vers mon service "login-ui-svc", et ainsi de suite.
On voit donc qu'avec un Ingress, on peut facilement exposer une multitude de services Web (mais aussi TCP et UDP, cf la documentation d'ingress-nginx) en utilisant une seule adresse IP, et donc en réduisant les coûts notamment dans le cloud.
¶ NetworkPolicies (cf plus bas)
Les stratégies réseau (NetworkPolicies, a.k.a NetPols) permettent de déterminer quels échanges réseaux sont autorisés entre pods, entre namespaces et entre services. On y reviendra plus en détail dans la partie "Sécurité" de ce module.
¶ Storage
Tout d'abord, il faut savoir que les containers qui composent nos pods sont censés être immutables. Ce qui signifie que si nous supprimons un pod (lors d'une RollingUpdate d'un Déploiement par exemple), les données que nous aurions pu stocker "dans" le pod seront supprimées. Dès lors, il était nécessaire de trouver un moyen d'assurer la persistence des données générées par nos pods (bases de données, données de site, etc).
Pour cela, Kubernetes est capable d'utiliser directement NFS ou iSCSI, mais aussi d'utiliser des classes de stockage permettant de provisionner des volumes de stockage à la volée et d'appliquer des règles de rétention de données (ou pas ), d'utiliser du stockage distant ou local, avec ou sans réplication des données stockées.
¶ StorageClass
Une StorageClass (Classe de Stockage) est une ressource définissant les paramètres de configuration d'un stockage (local ou distant) et fournissant une abstraction au cluster afin de pouvoir provisionner des Volumes Persistants (PV, PersistentVolume) automatiquement via des PersistentVolumeClaims (PVC).
On peut citer:
- rook-ceph (stockage local, crée un cluster Ceph avec le stockage des nodes du cluster)
- nfs-subdir-external-provisioner
- Longhorn (stockage local répliqué et montage via iSCSI)
- OpenEBS (stockage local répliqué et montage via iSCSI)
- MayaStor (stockage local répliqué)
- Piraeus Datastore (stockage local, réplication via DRBD, montage via Linstor)
- Netapp Trident
- Google Storage et ainsi de suite suivant votre fournisseur de cloud.
- local-path: stockage local par node, pas de réplication. Pratique pour tester.
¶ RWO, RWX, ROX: Les différents modes d'accès d'un Volume
Il existe plusieurs modes d'accès à un volume:
- ReadWriteMany: lecture/écriture par plusieurs pods. Attention, ça peut s'avérer dangereux, notamment dans le cas d'une base de données
- ReadWriteOnce: lecture/écriture par un seul pod. Une fois le volume monté, il ne peut pas être monté par un autre pod. Dès lors, dans le cas d'un déploiement, il n'est pas possible de profiter de la stratégie de mise à jour RollingUpdate.
- ReadOnlyMany: lecture seule. Donc aucun problème si plusieurs pods montent le volume pour y lire les données.
¶ PersistentVolume
Un Volume Persistant, PV, est une ressource du cluster qui peut être créée automatiquement par une StorageClass, ou manuellement par un opérateur humain (NFS ou iSCSI).
Cet objet est sans Namespace. Lorsqu'il est créé manuellement, il est de la forme:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-name
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy:
Retain
nfs:
path: /path/of/nfsmount/folder
server: 10.10.10.10 #IP or FQDN of NFS server
readOnly: false
---
Avantages de la méthode ci-dessus:
- Pas besoin de StorageClass
- Marche aussi avec iSCSI
- Facile à mettre en place
Désavantages:
- Provisionnement manuel:
- valable pour de tout petits déploiements/petits clusters
- difficile à maintenir
- error-prone
- Pas de réplication gérée par le cluster
¶ PersistentVolumeClaim
Une PersistentVolumeClaim (PVC, Réclamation de Volume Persistent) permet de lier un PV à un ou plusieurs pods (suivant le mode d'accès). Contrairement au PV, une PVC est une ressource "Namespacée". Attention, dans le cas de la création de plusieurs PVs et PVCs manuellement, les PVs et PVC sont liés en mode "premier servi, premier lié", ce qui peut engendrer des problèmes (PVC s'étant liée avec un volume plus petit que le volume prévu). Dès lors, il est important dans ce cas de bien spécifier dans la PVC le nom du PV auquel on veut se lier via la directive "volumeName":
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pv-name-pvc
namespace: enterprise
spec:
volumeName: "pv-name"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
---
Dans le cas de l'utilisation d'une StorageClass - dans l'exemple ci-dessous la SC "longhorn" - la déclaration de la PVC entraînera automatiquement la création du PV correspondant:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myvolume-pvc
namespace: enterprise
spec:
storageClassName: "longhorn"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
---
La suppression d'une PVC n'entraîne pas nécessairement la suppression du PV correspondant. Cela dépend de la Reclaim Policy configurée lors de la création du PV (ou configuré par la StorageClass): Retain ou Delete.
Bien évidemment, il est important de bien s'assurer que la bonne ReclaimPolicy - ou que l'on dispose de backups vérifiés - est utilisée avant toute suppression de PVC
¶ Montage dans le pod
Pour monter notre volume dans le pod, il faut tout d'abord le déclarer dans la spec du template des pods de notre Déploiement/Statefulset/Daemonset:
kind: Deployment
metadata:
# snip
spec:
# snip
template:
metadata:
labels:
mylabel: thisisalabel
spec:
securityContext:
# snip
volumes:
- name: my-volume-name
persistentVolumeClaim:
claimName: my-pvc-name
Ensuite, on déclare notre volume et son point de montage dans la définition du container voulu (si notre pod en compte plusieurs) de notre pod:
containers:
- name: containername
image: myrepo/myimage:mytag
securityContext:
#snip
ports:
- containerPort: 80
protocol: TCP
volumeMounts:
- name: my-volume-name
mountPath: /my/path/to/mount/my/volume
Et voilà
¶ ConfigMaps
Une Configmap est un objet contenant, dans un champ data, du texte, qui sera monté dans un fichier à l'intérieur de notre pod. Typiquement, il s'agira d'un fichier de configuration.
Par exemple, ci-dessous, une configmap définissant la configuration de PowerDNS (un serveur DNS):
apiVersion: v1
kind: ConfigMap
metadata:
name: pdns-auth-config
namespace: network
data:
pdnsconf: |
# database
launch=gpgsql
gpgsql-host=lidstah-info-pg-cluster.pgclusters.svc.cluster.local
gpgsql-port=5432
gpgsql-dbname=pdns
gpgsql-user=pdns
gpgsql-password=supermotdepassedelamort
gpgsql-extra-connection-parameters=sslmode=require
# listen on:
local-address=0.0.0.0:5353
#setup
master=yes
slave=no
allow-axfr-ips=127.0.0.1
# api and webserver
api=yes
api-key=powerdns
webserver=yes
webserver-address=0.0.0.0
webserver-password=supermotdepasseapikifaitpeur
webserver-port=8081
webserver-allow-from=127.0.0.1/8,::1,10.0.0.0/8,192.168.0.0/16
On va ensuite monter cette ConfigMap dans notre pod, comme on monterait un volume, ici, dans un DaemonSet:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: pdns-auth
namespace: network
spec:
selector:
matchLabels:
app: pdns-auth
template:
metadata:
labels:
app: pdns-auth
spec:
volumes:
- name: pdns-auth-conf
configMap:
name: pdns-auth-config
items:
- key: pdnsconf
path: pdns.conf
imagePullSecrets:
- name: dockerhub-creds
containers:
- name: pdns-auth
image: powerdns/pdns-auth-48:4.8.4
securityContext:
capabilities:
add: [ 'NET_ADMIN' ]
resources:
requests:
memory: "64Mi"
cpu: "50m"
volumeMounts:
- name: pdns-auth-conf
mountPath: /etc/powerdns
ports:
- containerPort: 8081
protocol: TCP
- containerPort: 53
protocol: UDP
restartPolicy: Always
---
Ainsi, nous pouvons facilement ajouter, à la création de nos pods par leurs Déploiements/StatefulSets/DaemonSets, des éléments de configuration sans avoir à monter de volume persistant via une PVC.
¶ Sécurité
¶ Pod Admission Controller et Pod Security Standard
¶ PSS: Pod Security Standard
Le PSS définit trois niveaux de privilèges pour un Pod:
- Privileged: le Pod peut, par défaut, contenir des conteneurs s'exécutant en mode privilégié, c'est à dire qu'ils peuvent modifier des paramètres de l'hôte (le noeud) sur lequel il s'exécute. Ce niveau de privilèges est en général requis par les pods en charge de l'infrastructure du cluster, par exemple, les pods d'un LoadBalancer (ex: MetalLB) qui doit pouvoir assigner des adresses IPs aux interfaces réseau du noeud sur lequel il s'exécute.
- Baseline: c'est une politique moins permissive que Privileged, se contentant de limiter les escalades de privilège classiques (un pod dont l'applicatif se lance en tant qu'utilisateur non-privilégié ne pourra pas effectuer l'équivalent d'un
sudo -s, ni lancer un exécutable SetUID (pour lancer le programme avec les droits d'un autre utilisateur)). - Restricted: Le pod doit exécuter ses applicatifs en tant qu'utilisateur non-privilégié, les systèmes de fichiers et notamment les volumes doivent être montés avec les droits d'un utilisateur non-privilégié et aucune capability du kernel ne doit être utilisée (ex: CAP_SYSADMIN). C'est le mode dans lequel, idéalement, on voudra exécuter nos charges de travail.
¶ PAC: Pod Admission Controller
Le Pod Admission Controller définit, au niveau du Namespace, quel Pod Security Standard s'applique aux pods. Il dispose de trois "modes" de fonctionnement:
- audit: Une violation de politique de sécurité (par exemple: un pod avec des droits de type Privileged s'exécute dans un Namespace où audit est configuré à Baseline) n'empêchera pas le Pod de se lancer mais génèrera un évènement dans le log d'audit.
- warn: Une violation de politique de sécurité déclenche un avertissement lorsque l'utilisateur déploie la ressource en question, mais n'empêche pas d'exécuter le pod.
- enforce: Une violation de politique de sécurité empêche le lancement du pod.
Par exemple, ce wiki s'exécute dans le namespace "web" de mon cluster Kubernetes. Le namespace "web" de mon cluster Kubernetes est défini ainsi:
kubectl describe namespace web
Name: web
Labels: kubernetes.io/metadata.name=web
pod-security.kubernetes.io/enforce=restricted
Annotations: <none>
Status: Active
No resource quota.
No LimitRange resource.
Ici, le label assigné au Namespace Web pod-security.kubernetes.io/enforce=restricted indique que tous les pods de ce namespace (le seul exposé à l'extérieur) doivent s'exécuter en mode non-privilégié, que leurs volumes persistants doivent être montés par un utilisateur non-privilégié, avec les droits correspondants, et qu'aucun des pods de ce Namespace ne doit utiliser des capacités du kernel (capabilities).
À l'inverse, le namespace metallb-system qui contient les pods de mon LoadBalancer, a lui comme définitions:
kubectl describe namespace metallb-system
Name: metallb-system
Labels: kubernetes.io/metadata.name=metallb-system
pod-security.kubernetes.io/audit=privileged
pod-security.kubernetes.io/enforce=privileged
pod-security.kubernetes.io/warn=privileged
Annotations: <none>
Status: Active
No resource quota.
No LimitRange resource.
Ici, on voit que les labels relatifs aux trois "modes" audit, enforce et warn sont configurés sur privileged. En effet, les pods de MetalLB doivent pouvoir modifier la configuration réseau de l'hôte, et pour ce faire, doivent s'exécuter en root, pour pouvoir modifier la configuration des interfaces réseau du noeud où ils se situent, afin d'attribuer les IPs "publiques" des services de type LoadBalancer qui seront créés sur notre cluster.
L'avantage de ce système est de pouvoir, en fonction du namespace, être sûr que ce qui s'exécute dans un namespace correspond bien aux politiques de sécurités voulues pour les pods appartenant à ce namespace.
Note: on peut modifier les labels de nos namespaces à chaud.
¶ RBAC
Kubernetes utilise RBAC - Role Based Access Control - comme mécanisme par défaut d'authentification.
Ce système permet un contrôle fin des droits de chaque utilisateur (humain ou non) du cluster, en définissant tout d'abord des Rôles donnant des permissions sur des éléments du cluster, des Comptes de Service (Service Accounts) pour nos utilisateurs (humains ou non), et des ClusterRolesBindings liant ces comptes de service à un ou plusieurs Rôles. Pour chaque compte de service, on créera un Token qui servira à authentifier notre Service Account, c'est à dire notre utilisateur.
Imaginons qu'un nouveau développeur rejoigne l'entreprise. Cet utilisateur doit avoir un accès à son propre espace de noms (Namespace), dans lequel il pourra faire ce qu'il veut, mais il ne doit pas avoir accès aux Namespaces d'autres utilisateurs, ni aux Namespaces de production ou d'administration du cluster.
Admettons que notre utilisateur s'appelle JeanMi, et qu'il doive donc avoir uniquement accès à l'espace de nom "jeanmi".
Nous allons d'abord créer son espace de nom (je vous laisse faire, ça devrait être automatique :p).
Ensuite, nous allons créer son compte de service, que nous appellerons… jeanmi
apiVersion: v1
kind: ServiceAccount
metadata:
name: jeanmi
namespace: jeanmi
Nous allons ensuite créer un Role, permettant à JeanMi d'accéder à son Namespace et d'y gérer toutes les ressources (Déploiements, Services, Secrets, PVC, etc) qu'il voudra y déployer:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: jeanmi-full-access
namespace: jeanmi
rules:
- apiGroups: ["", "extensions", "apps"]
resources: ["*"]
verbs: ["*"]
- apiGroups: ["batch"]
resources:
- jobs
- cronjobs
verbs: ["*"]
Enfin, nous allons créer le ClusterRoleBinding liant ce rôle à notre compte de service "jeanmi":
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: jeanmi-user-view
namespace: jeanmi
subjects:
- kind: ServiceAccount
name: jeanmi
namespace: jeanmi
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: jeanmi-full-access
Nous allons maintenant générer un token pour JeanMi:
kubectl create token -n jeanmi jeanmi
eyJhbGciOiJSUzI1NiIsImtpZCI6IkpDZWp4ZFJyVjg2cnRmZ0U0d3pZRzdUbE5uSW9qS2dJQkpMVmQxcE5Ya0kifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiLCJrM3MiXSwiZXhwIjoxNzQ2ODg3MzczLCJpYXQiOjE3NDY4OD
M3NzMsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwianRpIjoiYTIzY2VjM2MtODdkNi00MjEwLThhZDEtOTNlNjEyYjg2ZjAyIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJqZWFubWkiLCJzZXJ2aWNlYWNjb3VudCI6eyJ
uYW1lIjoiamVhbm1pIiwidWlkIjoiNDg4OTQ2NDMtZWU2MS00YTYwLWFjYWMtNzNjZjc3NmJmYTQ2In19LCJuYmYiOjE3NDY4ODM3NzMsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpqZWFubWk6amVhbm1pIn0.ZV9THHPtnOxPHbJgTVeTV0x6CZgYYbMj8kRYN4gcQ-P-YRvx
EUBFq_fDhp2iPBW8rb4KTVfCR3SvrXhIl51YW03jDEdQS8g523p4_HECRc6CZfm3QP7Dne52v3ag-xzp_lKvDGROM8E6E5P51tbf5la6vtuNIB9orWP5AYpWX165Je2zVjEbBuynJF8CjAHtzR3KgzR2g3FIC9EhDyhktbZDVOsvo6l-W_h-kC3kbxThvw6ggBsSWdpdIP0HRqTXzVDVx
eDnY1_LP3bJkE85fQuA6bdjfDo7yTrjK4JlGS0JoQg_wLzZGhY1N9TS7lIyY7L-xmbuYDdpk1VCTfCTcg
ouf! On va copier-coller ce token dans un fichier yaml de "Revue de Token" que nous allons soumettre à l'API:
apiVersion: authentication.k8s.io/v1
kind: TokenReview
metadata:
namespace: jeanmi
name: jeanmi-token
spec:
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IkpDZWp4ZFJyVjg2cnRmZ0U0d3pZRzdUbE5uSW9qS2dJQkpMVmQxcE5Ya0kifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiLCJrM3MiXSwiZXhwIjoxNzQ2ODg3MzczLCJpYXQiOjE3NDY4ODM3NzMsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwianRpIjoiYTIzY2VjM2MtODdkNi00MjEwLThhZDEtOTNlNjEyYjg2ZjAyIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJqZWFubWkiLCJzZXJ2aWNlYWNjb3VudCI6eyJuYW1lIjoiamVhbm1pIiwidWlkIjoiNDg4OTQ2NDMtZWU2MS00YTYwLWFjYWMtNzNjZjc3NmJmYTQ2In19LCJuYmYiOjE3NDY4ODM3NzMsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpqZWFubWk6amVhbm1pIn0.ZV9THHPtnOxPHbJgTVeTV0x6CZgYYbMj8kRYN4gcQ-P-YRvxEUBFq_fDhp2iPBW8rb4KTVfCR3SvrXhIl51YW03jDEdQS8g523p4_HECRc6CZfm3QP7Dne52v3ag-xzp_lKvDGROM8E6E5P51tbf5la6vtuNIB9orWP5AYpWX165Je2zVjEbBuynJF8CjAHtzR3KgzR2g3FIC9EhDyhktbZDVOsvo6l-W_h-kC3kbxThvw6ggBsSWdpdIP0HRqTXzVDVxeDnY1_LP3bJkE85fQuA6bdjfDo7yTrjK4JlGS0JoQg_wLzZGhY1N9TS7lIyY7L-xmbuYDdpk1VCTfCTcg
Pour le soumettre à l'API et vérifier que nous avons les droits voulus, nous allons exécuter la commande suivante:
kubectl apply -o yaml -f tokenreview.yaml
On devrait obtenir quelque chose du style:
apiVersion: authentication.k8s.io/v1
kind: TokenReview
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"authentication.k8s.io/v1","kind":"TokenReview","metadata":{"annotations":{},"name":"jeanmi-token"},"spec":{"token":"eyJhbGciOiJSUzI1NiIsImtpZCI6IkpDZWp4ZFJyVjg2cnRmZ0U0d3pZRzdUbE5uSW9qS2dJQkpMVmQxcE5Ya0kifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiLCJrM3MiXSwiZXhwIjoxNzQ2ODg3MzczLCJpYXQiOjE3NDY4ODM3NzMsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwianRpIjoiYTIzY2VjM2MtODdkNi00MjEwLThhZDEtOTNlNjEyYjg2ZjAyIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJqZWFubWkiLCJzZXJ2aWNlYWNjb3VudCI6eyJuYW1lIjoiamVhbm1pIiwidWlkIjoiNDg4OTQ2NDMtZWU2MS00YTYwLWFjYWMtNzNjZjc3NmJmYTQ2In19LCJuYmYiOjE3NDY4ODM3NzMsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpqZWFubWk6amVhbm1pIn0.ZV9THHPtnOxPHbJgTVeTV0x6CZgYYbMj8kRYN4gcQ-P-YRvxEUBFq_fDhp2iPBW8rb4KTVfCR3SvrXhIl51YW03jDEdQS8g523p4_HECRc6CZfm3QP7Dne52v3ag-xzp_lKvDGROM8E6E5P51tbf5la6vtuNIB9orWP5AYpWX165Je2zVjEbBuynJF8CjAHtzR3KgzR2g3FIC9EhDyhktbZDVOsvo6l-W_h-kC3kbxThvw6ggBsSWdpdIP0HRqTXzVDVxeDnY1_LP3bJkE85fQuA6bdjfDo7yTrjK4JlGS0JoQg_wLzZGhY1N9TS7lIyY7L-xmbuYDdpk1VCTfCTcg"}}
creationTimestamp: null
name: jeanmi-token
spec:
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IkpDZWp4ZFJyVjg2cnRmZ0U0d3pZRzdUbE5uSW9qS2dJQkpMVmQxcE5Ya0kifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiLCJrM3MiXSwiZXhwIjoxNzQ2ODg3MzczLCJpYXQiOjE3NDY4ODM3NzMsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwianRpIjoiYTIzY2VjM2MtODdkNi00MjEwLThhZDEtOTNlNjEyYjg2ZjAyIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJqZWFubWkiLCJzZXJ2aWNlYWNjb3VudCI6eyJuYW1lIjoiamVhbm1pIiwidWlkIjoiNDg4OTQ2NDMtZWU2MS00YTYwLWFjYWMtNzNjZjc3NmJmYTQ2In19LCJuYmYiOjE3NDY4ODM3NzMsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpqZWFubWk6amVhbm1pIn0.ZV9THHPtnOxPHbJgTVeTV0x6CZgYYbMj8kRYN4gcQ-P-YRvxEUBFq_fDhp2iPBW8rb4KTVfCR3SvrXhIl51YW03jDEdQS8g523p4_HECRc6CZfm3QP7Dne52v3ag-xzp_lKvDGROM8E6E5P51tbf5la6vtuNIB9orWP5AYpWX165Je2zVjEbBuynJF8CjAHtzR3KgzR2g3FIC9EhDyhktbZDVOsvo6l-W_h-kC3kbxThvw6ggBsSWdpdIP0HRqTXzVDVxeDnY1_LP3bJkE85fQuA6bdjfDo7yTrjK4JlGS0JoQg_wLzZGhY1N9TS7lIyY7L-xmbuYDdpk1VCTfCTcg
status:
audiences:
- https://kubernetes.default.svc.cluster.local
- k3s
authenticated: true
user:
extra:
authentication.kubernetes.io/credential-id:
- JTI=a23cec3c-87d6-4210-8ad1-93e612b86f02
groups:
- system:serviceaccounts
- system:serviceaccounts:jeanmi
- system:authenticated
uid: 48894643-ee61-4a60-acac-73cf776bfa46
username: system:serviceaccount:jeanmi:jeanmi
Enfin, il ne nous reste plus qu'à créer un utilisateur "jeanmi" sur notre machine de test:
useradd -ms /bin/bash jeanmi
sudo cp -r .kube /home/jeanmi/
sudo chown -R jeanmi: /home/jeanmi/.kube
sudo -s
su jeanmi
echo "export KUBECONFIG=/home/jeanmi/.kube/config" >>.bashrc
source .bashrc
nano .kube/config
Et modifier le fichier config de la sorte:
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUJkakNDQVIyZ0F3SUJBZ0lCQURBS0JnZ3Foa2pPUFFRREFqQWpNU0V3SHdZRFZRUUREQmhyTTNNdGMyVnkKZG1WeUxXTmhRREUzTkRZNE9ESTNNVEl3SGhjTk1qVXdOVEV3TVRNeE1UVXlXaGNOTXpVd05UQTRNVE14TVRVeQpXakFqTVNFd0h3WURWUVFEREJock0zTXRjMlZ5ZG1WeUxXTmhRREUzTkRZNE9ESTNNVEl3V1RBVEJnY3Foa2pPClBRSUJCZ2dxaGtqT1BRTUJCd05DQUFUSEdoQW9JNmpxMEpXQjQrZ3lIaW4vSFVCMXRuSjFtaEVaWnVGbzVPblMKcDJwTjJkQkVQU0hORWoxcnRST2ViTytpaXFRZ1FMZG1QR1M1cldvR05uZzlvMEl3UURBT0JnTlZIUThCQWY4RQpCQU1DQXFRd0R3WURWUjBUQVFIL0JBVXdBd0VCL3pBZEJnTlZIUTRFRmdRVWpnVEc5b0ZhOU11cXJaS1lWRXJHCmJHMnNxN2d3Q2dZSUtvWkl6ajBFQXdJRFJ3QXdSQUlnSUJFRjl3Tm1JajQvd3pZV244b0dlTzRNbmVNY1hkL0wKNkVVV25EaXplUFFDSUI1SG5wTHZxRlpxMk16WjZSaHFMaExYUitxc0ZRTUlGMWlwdDdFaU5QekEKLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=
server: https://127.0.0.1:6443
name: default
contexts:
- context:
cluster: default
user: jeanmi
namespace: jeanmi
name: default
current-context: default
kind: Config
preferences: {}
users:
- name: jeanmi
user:
client-key-data: LS0tLS1CRUdJTiBFQyBQUklWQVRFIEtFWS0tLS0tCk1IY0NBUUVFSUpKZlkzNVBQc1lGcjRFRzB6bVVEbVM2V2FPcVkwK2VZOG1ySjJYeHNRM2JvQW9HQ0NxR1NNNDkKQXdFSG9VUURRZ0FFMENGemc5NjF4SzBPSEFzSkZsQzN0VjdLSDVUeDRXM2UzSEVXOUxPU3FrOG1wOFhYTllGdgphcGxpZWtrbzRQNkRTejhVVUM1Q2RQUi9WYUwvWE1td2dBPT0KLS0tLS1FTkQgRUMgUFJJVkFURSBLRVktLS0tLQo=
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IkpDZWp4ZFJyVjg2cnRmZ0U0d3pZRzdUbE5uSW9qS2dJQkpMVmQxcE5Ya0kifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiLCJrM3MiXSwiZXhwIjoxNzQ2ODg3MzczLCJpYXQiOjE3NDY4ODM3NzMsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwianRpIjoiYTIzY2VjM2MtODdkNi00MjEwLThhZDEtOTNlNjEyYjg2ZjAyIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJqZWFubWkiLCJzZXJ2aWNlYWNjb3VudCI6eyJuYW1lIjoiamVhbm1pIiwidWlkIjoiNDg4OTQ2NDMtZWU2MS00YTYwLWFjYWMtNzNjZjc3NmJmYTQ2In19LCJuYmYiOjE3NDY4ODM3NzMsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpqZWFubWk6amVhbm1pIn0.ZV9THHPtnOxPHbJgTVeTV0x6CZgYYbMj8kRYN4gcQ-P-YRvxEUBFq_fDhp2iPBW8rb4KTVfCR3SvrXhIl51YW03jDEdQS8g523p4_HECRc6CZfm3QP7Dne52v3ag-xzp_lKvDGROM8E6E5P51tbf5la6vtuNIB9orWP5AYpWX165Je2zVjEbBuynJF8CjAHtzR3KgzR2g3FIC9EhDyhktbZDVOsvo6l-W_h-kC3kbxThvw6ggBsSWdpdIP0HRqTXzVDVxeDnY1_LP3bJkE85fQuA6bdjfDo7yTrjK4JlGS0JoQg_wLzZGhY1N9TS7lIyY7L-xmbuYDdpk1VCTfCTcg
Enfin, il ne nous reste plus qu'à tester si jeanmi a bien accès à son namespace, mais pas à d'autres:
kubectl get pods
# normalement rien
kubectl get ns
Error from server (Forbidden): namespaces is forbidden: User "system:serviceaccount:jeanmi:jeanmi" cannot list resource "namespaces" in API group "" at the cluster scope
# boum, jeanmi n'a pas le droit de regarder ailleurs
Bien évidemment, on peut adapter. On pourrait faire en sorte que jeanmi n'ait accès qu'à un déploiement, ou à un pod, ou qu'il ne puisse que lire les objets sans pouvoir les modifier, et ainsi de suite!
Cependant, vous vous rendrez vite compte que le token généré précédemment n'est que temporaire, ainsi que la TokenReview: ces données ne sont pas inscrites dans la base de données etcd du cluster.
Si on veut donner un accès constant à notre ami JeanMi, nous allons devoir créer un Secret lié au ServiceAccount de JeanMi, dans le Namespace "jeanmi" de la sorte:
apiVersion: v1
kind: Secret
type: kubernetes.io/service-account-token
metadata:
name: jeanmitoken
namespace: jeanmi
annotations:
kubernetes.io/service-account.name: jeanmi
On applique notre yaml via kubectl apply -f nomdufichier.yaml puis, on va récupérer notre nouveau token (qui lui, sera durable dans le temps):
kubectl describe secret -n jeanmi jeanmitoken
Name: jeanmitoken
Namespace: jeanmi
Labels: <none>
Annotations: kubernetes.io/service-account.name: jeanmi
kubernetes.io/service-account.uid: 48894643-ee61-4a60-acac-73cf776bfa46
Type: kubernetes.io/service-account-token
Data
====
namespace: 6 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IkpDZWp4ZFJyVjg2cnRmZ0U0d3pZRzdUbE5uSW9qS2dJQkpMVmQxcE5Ya0kifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJqZWFubWkiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlY3JldC5uYW1lIjoiamVhbm1pdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiamVhbm1pIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiNDg4OTQ2NDMtZWU2MS00YTYwLWFjYWMtNzNjZjc3NmJmYTQ2Iiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50OmplYW5taTpqZWFubWkifQ.izPJBgeFAksRBbJiOaRQFiHeFAEWZsvC-teAwbvPM_6NLrJPtp7EAFDEhboE8lANHZUrWMCLREFL5EzRXEGK0U4zdA0ZPocGaEXdPlYDUl3SKDJAPaIbs2rDuxxyrsw2K8HCmgIlPQjuuXs6M9d4dIWURbRJoJYQ8bzt0fcxJqYIZ2O_AHGN4vCSeiCvvo-IejQkUrru6uC6J0KXdtwYFB2pQHKNX3RzGNpZf3a55pP_Gn5mVm6yba1MzSa17T8VUm087_x0-MDncDRt1Ru_9sgwL6McPQvtA9_6kJqYS5McQ_ZPd3PGttKx8sJCWnIb-f81Cg9XBMSgcDbF6m19XA
ca.crt: 566 bytes
On remplace ensuite dans notre fichier /home/jeanmi/.kube/config le token généré précédemment par le token présent dans notre secret, et voilà! Il ne nous reste plus qu'à confier à JeanMi son fichier kubeconfig (de façon sécurisée, pas dans un mail ).
C'est un mécanisme très puissant, qui nécessiterait un module à part entière!
¶ NetworkPolicies (the comeback)
Les Politiques Réseau, NetworkPolicies, vont nous permettre de gérer le trafic tant au niveau 3 du modèle OSI (IP) qu'au niveau 4 (ports: TCP, UDP, etc), et de définir qui peut discuter avec qui:
- Quels pods peuvent discuter entre eux (exception: un pod ne peut pas se "bannir" lui même!)
- Quels Namespaces (et les pods à l'intérieur) peuvent communiquer entre eux, ou pas. (Par défaut, tout le monde peut papoter avec tout le monde)
- Quels blocs d'IPs peuvent discuter à l'intérieur du cluster (attention, un Pod ignorera cette Network Policy s'il doit discuter avec un Pod situé sur le même noeud) comme à l'extérieur (exemple: je veux autoriser le trafic vers et en provenance de 192.168.1.0/24 mais interdire celui en provenance de 192.168.2.0/24)
Pour cela, nous pouvons agir sur les politiques d'entrée (Ingress) et de sortie (Egress).
Par exemple, pour interdire par défaut tout trafic en entrée de tous nos pods appartenant au namespace "testing":
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: testing-deny-all-ingress
namespace: testing
spec:
podSelector: {}
policyTypes:
- Ingress
De la même manière, pour empêcher tout pod de notre namespace "testing" de pouvoir envoyer du trafic vers l'extérieur:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: testing-deny-all-egress
namespace: testing
spec:
podSelector: {}
policyTypes:
- Egress
On peut résumer ces deux Network Policies de la sorte:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: testing-deny-all
namespace: testing
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
Bon, disons que là, c'est l'équivalent de s'enfermer dehors avec iptables: nous ne pouvons envoyer ou recevoir aucun trafic, y compris entre pods du même namespace.
Pour pouvoir, par exemple, autoriser le trafic en entrée sur tous nos pods, en provenance du même namespace:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: testing-allow-same-namespace-ingress
namespace: testing
spec:
podSelector: {}
policyTypes:
- Ingress
ingress:
- from:
- podSelector: {}
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: testing-allow-same-namespace-egress
namespace: testing
spec:
podSelector: {}
policyTypes:
- Egress
egress:
- from:
- podSelector: {}
Au moins, nos pods devraient pouvoir discuter entre eux, à l'intérieur du même namespace, mais pas avec les namespaces extérieurs.
Supprimons nos Network Policies avec un kubectl delete networkpolicy -n testing suivi des noms de nos NetworkPolicies (que je vais abréger NetPol dans la suite).
Imaginons maintenant que nous voulons autoriser le trafic en entrée uniquement sur nos pods portant le label "role: webapp", en provenance de notre Ingress et donc du namespace "ingress-nginx" auquel nous ajouterons le label "purpose: ingress":
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: testing-allow-ingress-namespace
namespace: testing
spec:
podSelector:
matchLabels:
role: webapp
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
purpose: ingress
De la même façon, nous pourrions n'autoriser nos pods de notre namespace à n'envoyer du trafic (donc, en egress), qu'à nos pods portant le label "role: db":
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: testing-allow-egress-db
namespace: testing
spec:
podSelector:
matchLabels:
role: backend
policyTypes:
- Egress
egress:
- to:
- podSelector:
matchLabels:
role: db
On peut aussi "mixer" différents sélecteurs, par exemple, n'autoriser l'egress (ou l'ingress) que vers les pods portant le label "role: db" et appartenant au subnet 10.42.2.0/24, sauf 10.42.2.10/32:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: testing-allow-egress-db-except-oneip
namespace: testing
spec:
podSelector:
matchLabels:
role: backend
policyTypes:
- Egress
egress:
- to:
- podSelector:
matchLabels:
role: db
- ipBlock:
cidr: 10.42.2.0/24
except:
- 10.42.2.10/32
Les possibilités sont assez fines, et on peut ainsi vraiment gérer les communications entre nos pods, nos espaces de noms, nos sous-réseaux de façon assez fine.
On peut par exemple imaginer un cluster où nous hébergeons des services pour différents clients, par exemple client1 et client2, chacun dans son namespace, et isoler le trafic pour éviter toute possibilité pour client1 ou client2 d'aller discuter avec les pods de l'autre client.
¶ Secrets, ConfigMaps: qualités et défauts à prendre en compte.
Si les ConfigMaps sont très pratiques, elles ont un défaut: elles sont "en clair", et donc toute personne ayant les accès nécessaires pourra y lire les secrets (mots de passes, tokens, etc) présents dans cette ConfigMap. De même, dans une infrastructure orientée GitOps, on ne voudra jamais "commit" de secrets en clair!
De même, les Secrets Kubernetes sont eux aussi triviaux: ils sont simplement encodés en Base 64. Cependant, à l'inverse des configmaps, ils sont appelés par exemple dans les variables d'environnement de nos pods, ce qui nous permet, toujours dans le cas d'une infrastructure de type GitOps, de sereinement commiter nos Déploiements/etc sans y laisser d'informations sensibles.
De la même façon, les Secrets de type TLS nous permettent, eux, de stocker certificats et clefs privées TLS, secrets qui seront ensuite "montés" comme une ConfigMap dans nos pods.
Pour créer un secret de type générique depuis la ligne de commande, définissant deux champs "user" et "pass" (attention, les valeurs sont en clair et apparaîtront dans l'historique de votre shell!! note: si vous précédez votre commande d'un espace, elle n'apparaîta pas dans l'historique):
kubectl create secret generic -n monns mon-super-secret --from-literal=user=jeanmi \
--from-literal=password=azerty1234
On peut aussi, au lieu de --from-literal=... utiliser --from-file, etc. Je vous invite à consulter la documentation de Kubernetes concernant les secrets ici:
https://kubernetes.io/docs/concepts/configuration/secret/
Pour créer le même secret en Yaml:
apiVersion: v1
kind: Secret
metadata:
namespace: monns
name: mon-super-secret
data:
user: amVhbm1pCg==
pass: YXplcnR5MTIzNAo=
Notez qu'ici, on a préalablement encodé en base64 nos secrets. Attention, ce n'est pas du chiffrement!! Et bien évidemment, on ne voudra pas commiter en clair ce genre de chose! Il sera donc nécessaire de chiffrer ces secrets, par exemple en utilisant GPG.
Maintenant, pour monter mon secret, par exemple dans une variable d'environnement de mon StatefulSet MariaDB:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mariadb-test
namespace: maria
spec:
selector:
matchLabels:
app: mariadb-test
serviceName: "maria-svc"
replicas: 1
template:
metadata:
labels:
app: mariadb-test
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mariadb
image: mariadb:10.5
env:
- name: "MARIADB_ROOT_PASSWORD"
valueFrom:
secretKeyRef:
name: my-db-secret
key: dbrootpass
- name: "MARIADB_DATABASE"
value: "epsi"
- name: "MARIADB_PASSWORD"
valueFrom:
secretKeyRef:
name: my-db-secret
key: dbpass
- name: "MARIADB_USER"
value: "epsi"
ports:
- containerPort: 3306
name: mariadb
protocol: TCP
volumeMounts:
- name: maria
mountPath: /var/lib/mysql
volumeClaimTemplates:
- metadata:
name: maria
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs-client"
resources:
requests:
storage: 2Gi
C'est quand même mieux de ne pas avoir en clair nos mots de passe dans notre StatefulSet, non?
Exercice: faites la même chose pour le nom de la base de données et de l'utilisateur
Enfin, si je dispose de deux fichiers: monsite.crt et monsite.key contenant respectivement mon certificat public et ma clef privée pour mon serveur Web afin d'avoir du beau HTTPS, je peux créer un secret les contenant que je pourrai ensuite utiliser avec, par exemple, mon Ingress:
kubectl create secret tls -n monns mon-certif --key=./monsite.key --cert=./monsite.crt
¶ Extensions de l'API: Opérateurs et Custom Resources Definitions
Les opérateurs nous permettent d'étendre les fonctionnalités de l'API de kubernetes, afin de pouvoir créer des objets qui ne sont pas fournis par défaut par Kubernetes.
Par exemple, pouvoir créer rapidement un cluster postgresql et gérer son cycle de vie ne sont pas des possibilités fournies par défaut par Kubernetes - cela ne fait pas partie du périmètre défini par la Cloud Native Computing Foundation dans le développement de Kubernetes. Par contre, la CNCF a prévu la possibilité d'étendre les fonctionnalités de Kubernetes via un mécanisme: les Custom Resources Definitions et les Operators, qui vont nous permettre de créer des ressources plus "abstraites" (ex: un cluster postgresql) que l'opérateur va transformer en ressources consommables par l'API de Kubernetes.
Par exemple, la base postgres de ce wiki est gérée par l'opérateur Zalando PostgreSQL:
kubectl get postgresqls -n pgclusters
NAME TEAM VERSION PODS VOLUME CPU-REQUEST MEMORY-REQUEST AGE STATUS
lidstah-info-pg-cluster acid 15 2 100Gi 100m 128Mi 2y90d Running
L'opérateur ZPG ici m'a permis de créer un cluster postgres composé de deux StatefulSets, disposant chacun d'un volume de 100Go, réservant au minimum 10% de CPU et 128Mo de RAM pour leur fonctionnement. La version utilisée actuellement est la version 15 de PostgreSQL, que j'ai pu mettre à jour en quelques clics depuis la version 13 que j'utilisai précedemment (après avoir fait un backup, quand même!!).
Il existe une pléthore d'opérateurs, par exemple:
- wireguard operator: créer des serveurs VPNs basés sur wireguard ainsi que les configurations utilisateurs
- ECK Operator: ElasticSearch, Kibana, Logstash, pour créer, gérer et administrer des clusters ElasticSearch, Kibana, Logstash rapidement directement dans Kubernetes
- Zalando PostgreSQL operator: il se passe de commentaire
- CrunchyData PostgreSQL operator: le concurrent, très bon aussi.
- MariaDB Operator: la même chose mais pour MariaDB (+galera).